// FD is a file descriptor. The net and os packages use this type as a // field of a larger type representing a network connection or OS file. type FD struct { // Lock sysfd and serialize access to Read and Write methods. fdmu fdMutex
// System file descriptor. Immutable until Close. Sysfd int
// I/O poller. pd pollDesc
// Writev cache. iovecs *[]syscall.Iovec
// Semaphore signaled when file is closed. csema uint32
// Non-zero if this file has been set to blocking mode. isBlocking uint32
// Whether this is a streaming descriptor, as opposed to a // packet-based descriptor like a UDP socket. Immutable. IsStream bool
// Whether a zero byte read indicates EOF. This is false for a // message based socket connection. ZeroReadIsEOF bool
// Whether this is a file rather than a network socket. isFile bool }
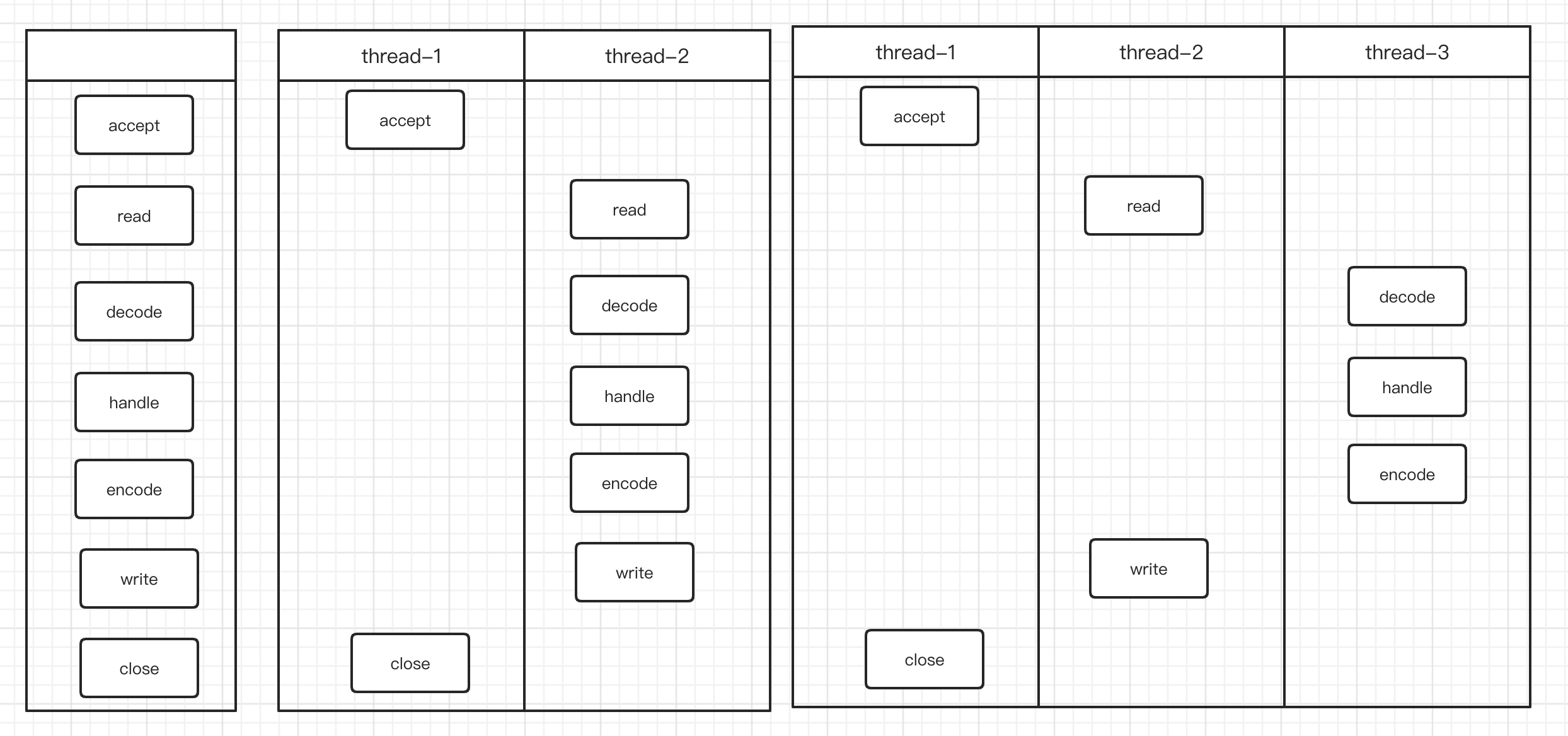
1 2 3
type pollDesc struct { runtimeCtx uintptr }
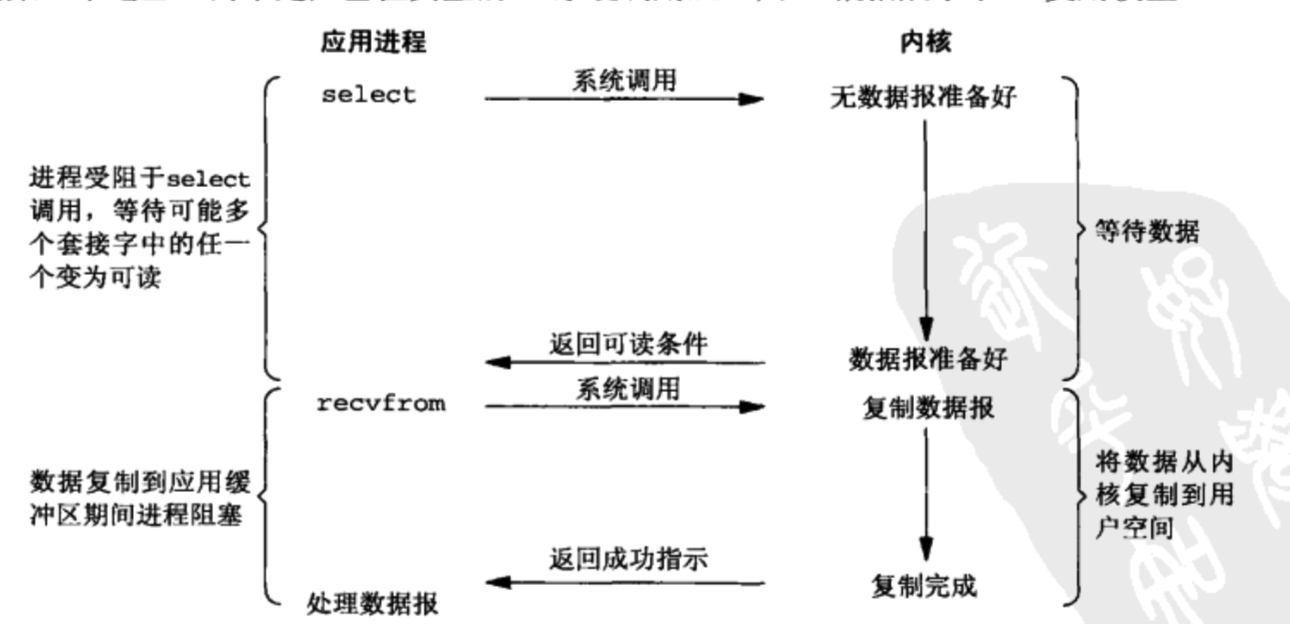
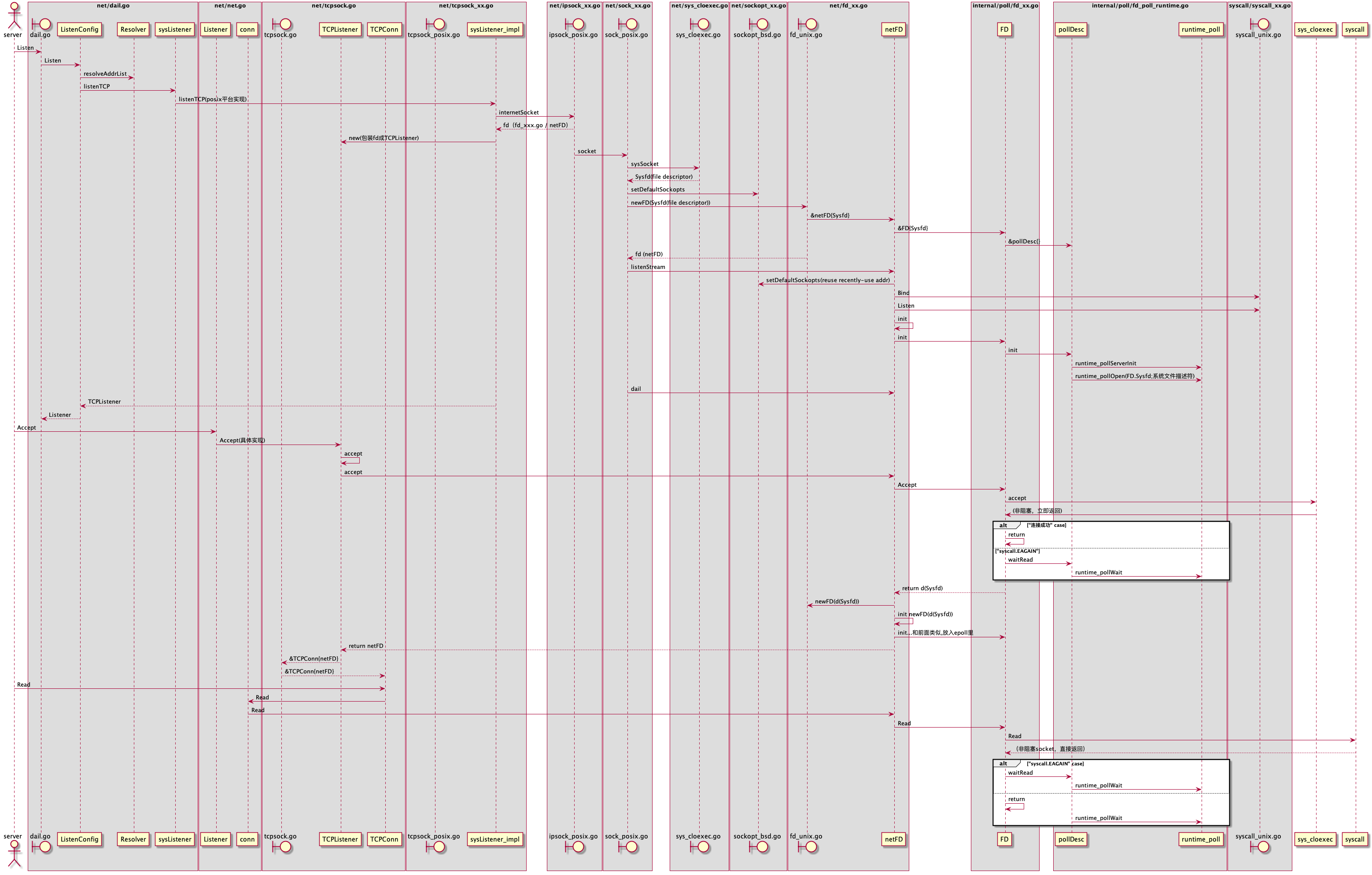
netpoll 是如何通过 park goroutine 从而达到阻塞 Accept/Read/Write 的效果,通过调用 gopark,goroutine 会被放置在某个等待队列中(如 channel 的 waitq ,此时 G 的状态由 _Grunning 为 _Gwaitting )
// Network poller descriptor. // // No heap pointers. // //go:notinheap type pollDesc struct { link *pollDesc // in pollcache, protected by pollcache.lock
// The lock protects pollOpen, pollSetDeadline, pollUnblock and deadlineimpl operations. // This fully covers seq, rt and wt variables. fd is constant throughout the PollDesc lifetime. // pollReset, pollWait, pollWaitCanceled and runtime·netpollready (IO readiness notification) // proceed w/o taking the lock. So closing, everr, rg, rd, wg and wd are manipulated // in a lock-free way by all operations. // NOTE(dvyukov): the following code uses uintptr to store *g (rg/wg), // that will blow up when GC starts moving objects. lock mutex // protects the following fields fd uintptr closing bool everr bool// marks event scanning error happened user uint32// user settable cookie rseq uintptr// protects from stale read timers rg uintptr// pdReady, pdWait, G waiting for read or nil rt timer // read deadline timer (set if rt.f != nil) rd int64// read deadline wseq uintptr// protects from stale write timers wg uintptr// pdReady, pdWait, G waiting for write or nil wt timer // write deadline timer wd int64// write deadline }
#include <sys/epoll.h> int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
//go:linkname poll_runtime_pollWait internal/poll.runtime_pollWait funcpoll_runtime_pollWait(pd *pollDesc, mode int)int { err := netpollcheckerr(pd, int32(mode)) if err != 0 { return err } // As for now only Solaris, illumos, and AIX use level-triggered IO. if GOOS == "solaris" || GOOS == "illumos" || GOOS == "aix" { netpollarm(pd, mode) } // 进入 netpollblock 并且判断是否有期待的 I/O 事件发生, // 这里的 for 循环是为了一直等到 io ready for !netpollblock(pd, int32(mode), false) { err = netpollcheckerr(pd, int32(mode)) if err != 0 { return err } // Can happen if timeout has fired and unblocked us, // but before we had a chance to run, timeout has been reset. // Pretend it has not happened and retry. } return0 }
// returns true if IO is ready, or false if timedout or closed // waitio - wait only for completed IO, ignore errors funcnetpollblock(pd *pollDesc, mode int32, waitio bool)bool { // gpp 保存的是 goroutine 的数据结构 g,这里会根据 mode 的值决定是 rg 还是 wg // 后面调用 gopark 之后,会把当前的 goroutine 的抽象数据结构 g 存入 gpp 这个指针 gpp := &pd.rg if mode == 'w' { gpp = &pd.wg }
// set the gpp semaphore to WAIT // 这个 for 循环是为了等待 io ready 或者 io wait for { old := *gpp // gpp == pdReady 表示此时已有期待的 I/O 事件发生, // 可以直接返回 unblock 当前 goroutine 并执行响应的 I/O 操作 if old == pdReady { *gpp = 0 returntrue } if old != 0 { throw("runtime: double wait") } // 如果没有期待的 I/O 事件发生,则通过原子操作把 gpp 的值置为 pdWait 并退出 for 循环 if atomic.Casuintptr(gpp, 0, pdWait) { break } }
// need to recheck error states after setting gpp to WAIT // this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl // do the opposite: store to closing/rd/wd, membarrier, load of rg/wg
// waitio 此时是 false,netpollcheckerr 方法会检查当前 pollDesc 对应的 fd 是否是正常的, // 通常来说 netpollcheckerr(pd, mode) == 0 是成立的,所以这里会执行 gopark // 把当前 goroutine 给 park 住,直至对应的 fd 上发生可读/可写或者其他『期待的』I/O 事件为止, // 然后 unpark 返回,在 gopark 内部会把当前 goroutine 的抽象数据结构 g 存入 // gpp(pollDesc.rg/pollDesc.wg) 指针里,以便在后面的 netpoll 函数取出 pollDesc 之后, // 把 g 添加到链表里返回,接着重新调度 goroutine if waitio || netpollcheckerr(pd, mode) == 0 { // 注册 netpollblockcommit 回调给 gopark,在 gopark 内部会执行它,保存当前 goroutine 到 gpp gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5) } // be careful to not lose concurrent READY notification old := atomic.Xchguintptr(gpp, 0) if old > pdWait { throw("runtime: corrupted polldesc") } return old == pdReady }
// gopark 会停住当前的 goroutine 并且调用传递进来的回调函数 unlockf,从上面的源码我们可以知道这个函数是 // netpollblockcommit funcgopark(unlockf func(*g, unsafe.Pointer)bool, lockunsafe.Pointer, reasonwaitReason, traceEvbyte, traceskipint) { if reason != waitReasonSleep { checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy } mp := acquirem() gp := mp.curg status := readgstatus(gp) if status != _Grunning && status != _Gscanrunning { throw("gopark: bad g status") } mp.waitlock = lock mp.waitunlockf = unlockf gp.waitreason = reason mp.waittraceev = traceEv mp.waittraceskip = traceskip releasem(mp) // can't do anything that might move the G between Ms here. // gopark 最终会调用 park_m,在这个函数内部会调用 unlockf,也就是 netpollblockcommit, // 然后会把当前的 goroutine,也就是 g 数据结构保存到 pollDesc 的 rg 或者 wg 指针里 mcall(park_m) }
// park continuation on g0. funcpark_m(gp *g) { _g_ := getg()
if trace.enabled { traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip) }
casgstatus(gp, _Grunning, _Gwaiting) dropg()
if fn := _g_.m.waitunlockf; fn != nil { // 调用 netpollblockcommit,把当前的 goroutine, // 也就是 g 数据结构保存到 pollDesc 的 rg 或者 wg 指针里 ok := fn(gp, _g_.m.waitlock) _g_.m.waitunlockf = nil _g_.m.waitlock = nil if !ok { if trace.enabled { traceGoUnpark(gp, 2) } casgstatus(gp, _Gwaiting, _Grunnable) execute(gp, true) // Schedule it back, never returns. } } schedule() }
// netpollblockcommit 在 gopark 函数里被调用 funcnetpollblockcommit(gp *g, gpp unsafe.Pointer)bool { // 通过原子操作把当前 goroutine 抽象的数据结构 g,也就是这里的参数 gp 存入 gpp 指针, // 此时 gpp 的值是 pollDesc 的 rg 或者 wg 指针 r := atomic.Casuintptr((*uintptr)(gpp), pdWait, uintptr(unsafe.Pointer(gp))) if r { // Bump the count of goroutines waiting for the poller. // The scheduler uses this to decide whether to block // waiting for the poller if there is nothing else to do. atomic.Xadd(&netpollWaiters, 1) } return r }
for { // 取出 gpp 存储的 g old := *gpp if old == pdReady { returnnil } if old == 0 && !ioready { // Only set READY for ioready. runtime_pollWait // will check for timeout/cancel before waiting. returnnil } varnewuintptr if ioready { new = pdReady } // 重置 pollDesc 的 rg 或者 wg if atomic.Casuintptr(gpp, old, new) { if old == pdReady || old == pdWait { old = 0 } // 通过万能指针还原成 g 并返回 return (*g)(unsafe.Pointer(old)) } } }
// One round of scheduler: find a runnable goroutine and execute it. // Never returns. funcschedule() { // ...
if gp == nil { gp, inheritTime = findrunnable() // blocks until work is available }
// ... }
// Finds a runnable goroutine to execute. // Tries to steal from other P's, get g from global queue, poll network. funcfindrunnable()(gp *g, inheritTime bool) { // ...
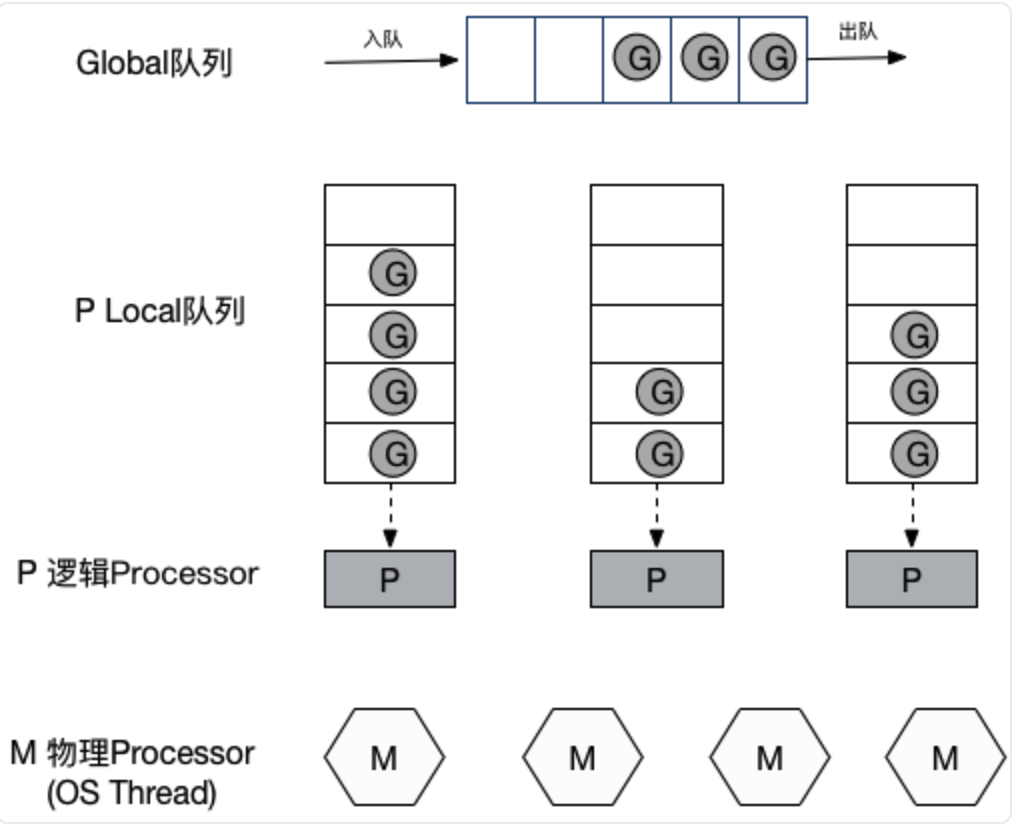
// Poll network. // This netpoll is only an optimization before we resort to stealing. // We can safely skip it if there are no waiters or a thread is blocked // in netpoll already. If there is any kind of logical race with that // blocked thread (e.g. it has already returned from netpoll, but does // not set lastpoll yet), this thread will do blocking netpoll below // anyway. if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { if list := netpoll(false); !list.empty() { // non-blocking gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false } }
// Always runs without a P, so write barriers are not allowed. // //go:nowritebarrierrec funcsysmon() { // ... now := nanotime() if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now { atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now)) // 以非阻塞的方式调用 netpoll 获取就绪 fd 列表 list := netpoll(false) // non-blocking - returns list of goroutines if !list.empty() { // Need to decrement number of idle locked M's // (pretending that one more is running) before injectglist. // Otherwise it can lead to the following situation: // injectglist grabs all P's but before it starts M's to run the P's, // another M returns from syscall, finishes running its G, // observes that there is no work to do and no other running M's // and reports deadlock. incidlelocked(-1) // 将其插入调度器的runnable列表中(全局),等待被调度执行 injectglist(&list) incidlelocked(1) } } // retake P's blocked in syscalls // and preempt long running G's if retake(now) != 0 { idle = 0 } else { idle++ } // check if we need to force a GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 { lock(&forcegc.lock) forcegc.idle = 0 var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now { lasttrace = now schedtrace(debug.scheddetail > 0) } } }