这边笔记涵盖了以下内容:
- 容器虚拟化的原理
- 容器编排的基本概念
- k8s的容器编排对象
- k8s的集群架构和基本原理
- 容器编排的实践
参考学习材料
- 《docker进阶与实战》
《kubernetes in action》ch1-ch11
极客时间《深入剖析Kubernetes》
容器&docker
docker的虚拟化原理
Namespace 做隔离,Cgroups 做限制,rootfs 做文件系统
本质上依然是一个进程
Namespace 做隔离
namespace用于对全局资源的隔离
已经有的:
- ipc
- network
- mount
- pid
- uts
- user
通常的操作:
clone: 创建新的namespance
setns:把进程放进已有的namespace里
Cgroups 做限制
cpuset子系统:限制可用的cpu列表
cpu子系统:限制cpu利用率
memory子系统:限制内存使用率
…
rootfs 做文件系统
进程使用pivot_root系统调用来做跟文件系统的切换
(union mount来分层镜像)
容器编排&kubernetes
什么是容器编排(Container Orchestration)
容器编排是为了简化服务的开发和运维,提升基础设施利用率的工具。
容器编排核心关注的是以下几个点
Workloads
Scheduler
Networking
Storage
workloads是最小的部署单元,比如我们手动在服务器上启动web服务:python manager runserver,可以认为最小的部署单元是一个进程。workloads包含了network/memory/cpu等资源的需求。
scheduler主要功能有三个:
- 控制着workloads的生命周期,包括创建,销毁,health check
- 控制着workloads之间的约束关系:Coordination/Replica/Dependency
- workloads的扩容缩容/更新/回滚等
Networks关注集群的网络模型(L3/L4)/DNS/service discovery/load balance
存储主要分为volumn & persistence volumn
kubernetes是起源于google的borg&omega的容器编排工具
kubernetes的集群架构
从硬件角度看,一个kubernetes集群有很多节点(node)组成,每个节点可以是物理机/虚拟机,这些节点被分为两种类型:
master:集群的管理
worker:运行用户实际部署的应用
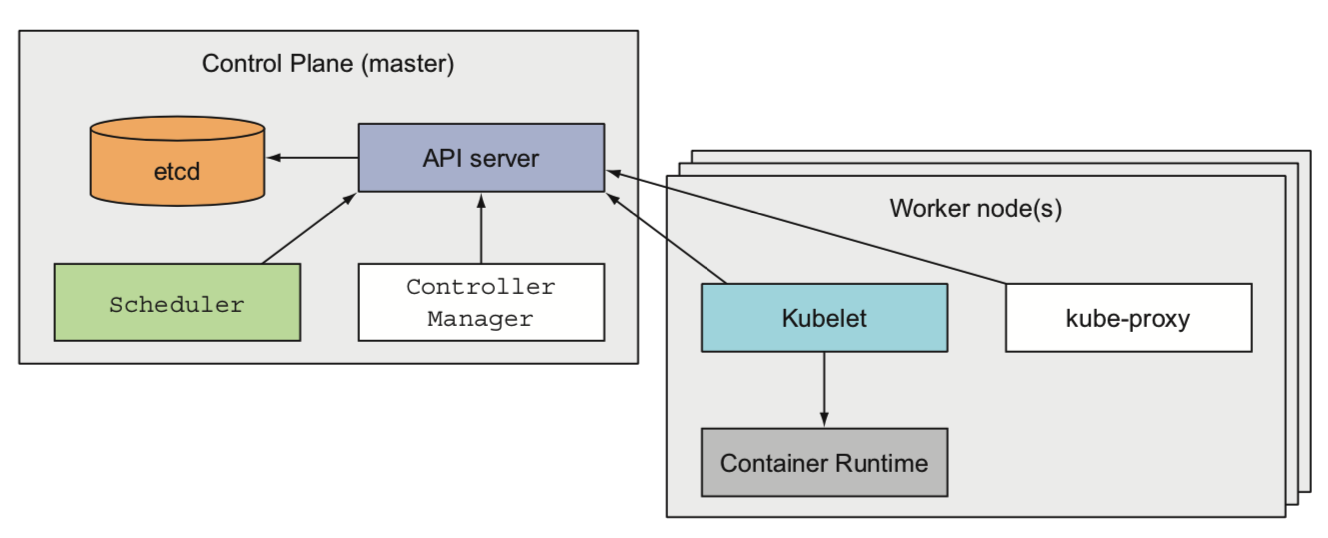
master主要有四个组件
- etcd:提供线性一致性的存储,用于存储集群的配置信息/leader 选举
- api server:etcd的代理,提供etcd的配置变更接口,变更监听的能力
- scheduler:调度应用(给应用分配可部署的节点)
- controller manager:跟踪工作节点,处理工作节点失效等集群的功能
worker nodes主要有三个组件
kubelet:管理节点的容器
kube-proxy:组件之间的负载均衡网络流量
Container runtime:容器运行时
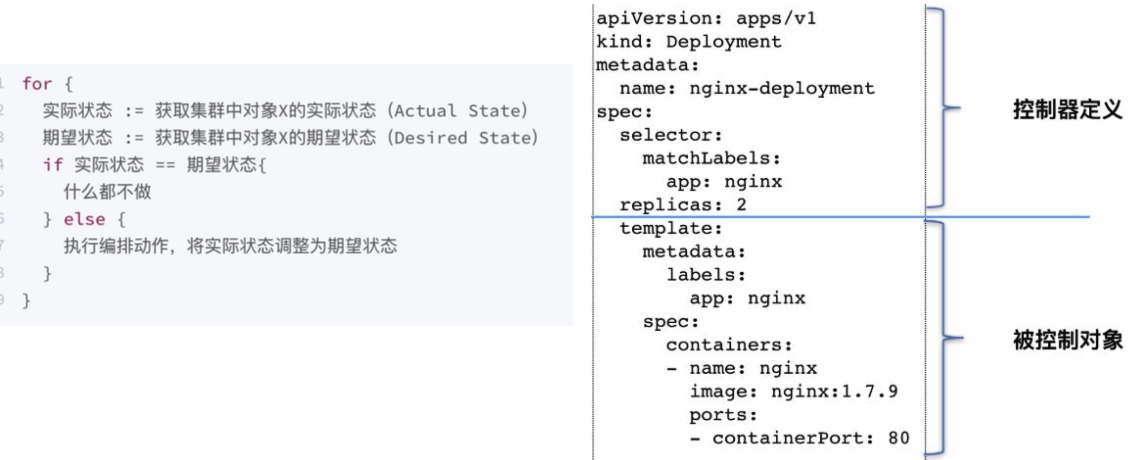
kubernetes的资源对象
kubernetes的资源对象包括了pod/deployment/service等等各种各样的资源。
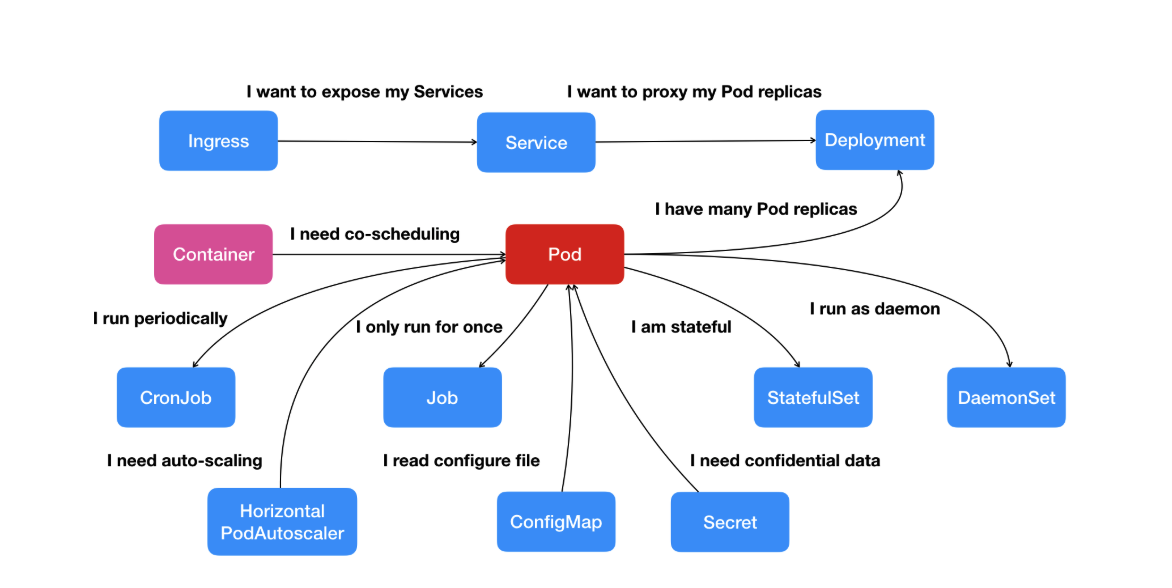
kubernetes的资源对象都是通过yaml或者json描述文件来创建的,kubebctl也提供了一些简单的命令创建一组属性有限的资源对象。
1. pod - 最小的调度单位(workloads)
pod的结构
kubernetes使用pod作为最小调度单位,pod是一组共享了某些资源的容器
具体的说,共享了net/uts/ipc/pid namespace,所以具有相同的loopback网络接口,可以进行ipc通信等,但是挂载文件系统是隔离的(文件系统来自于容器镜像)
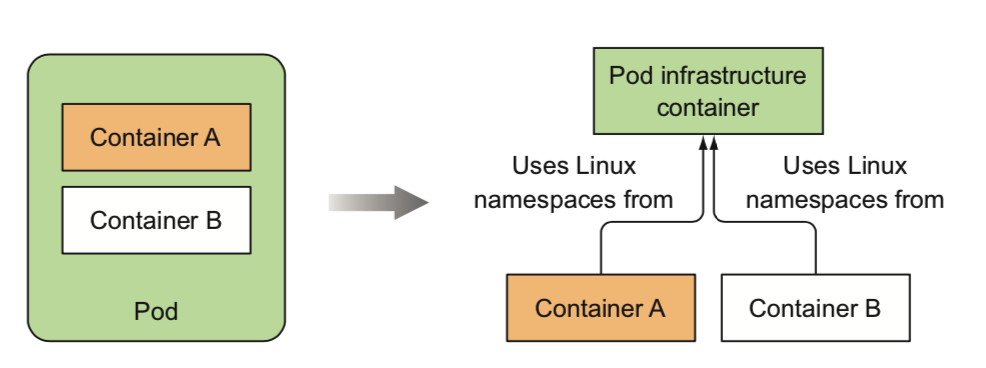
- pod里的容器必须运行在相同的节点,解决了成组调度的问题
- Infra 容器是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右
- pod之间的网络没有NAT转换
- Pod 扮演的是传统部署环境里“虚拟机”的角色,调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的
容器设计模式
主容器运行应用,sidecar进程运行住进程之外的工作
eg:
- war && tomcat
- 应用和日志搜集
- istio sidecar
pod的资源描述
1 | apiVersion: v1 # api版本 |
使用命名空间对资源进行分组(没有隔离作用)
使用标签和选择器来约束pod的调度
1
2
3spec:
nodeSelector:
labelKey: labelValue
2. deployment - 声明式的升级应用
从replicationController(rc)说起
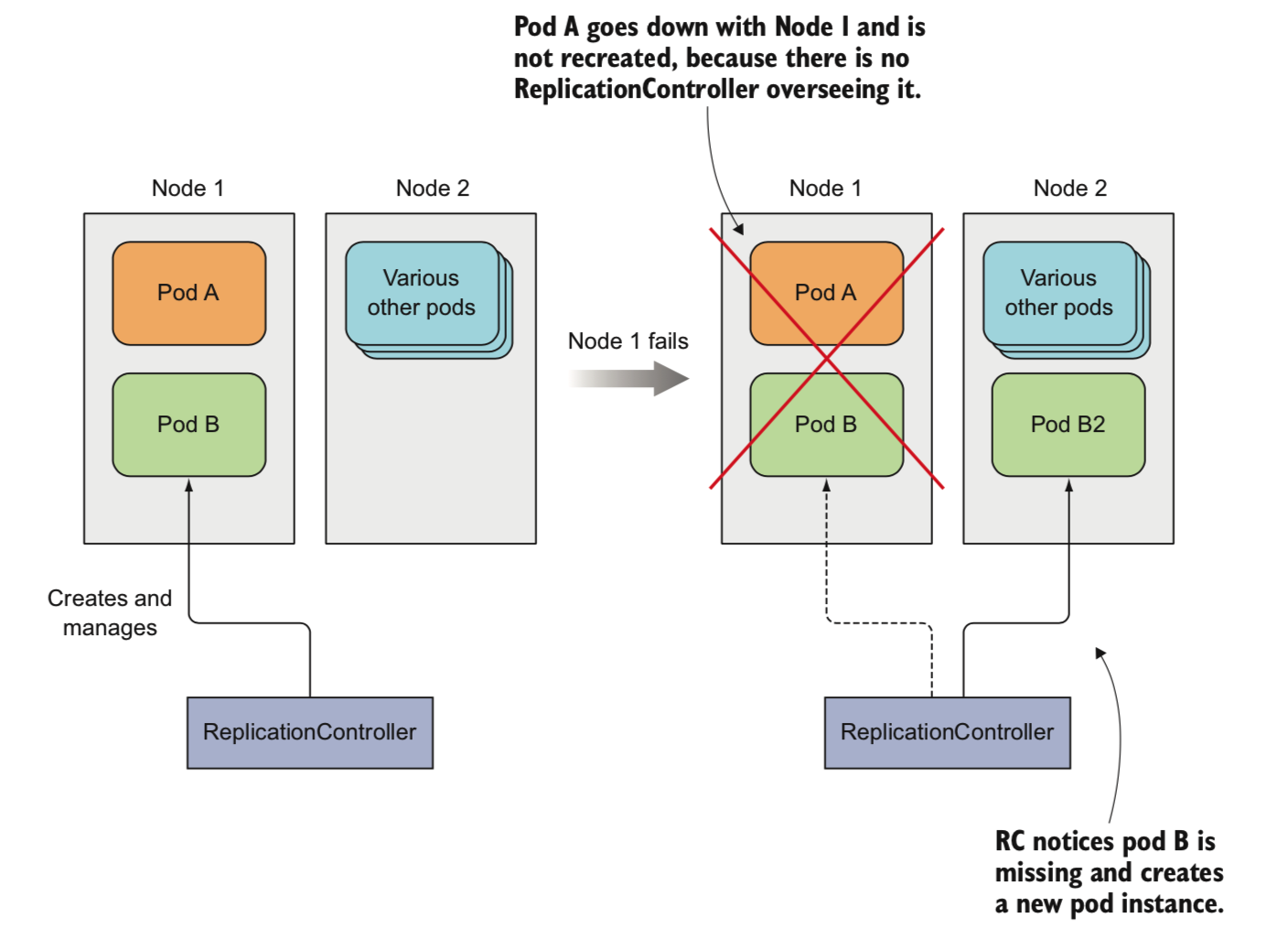
通过给pod配置存活探针,kubernetes检测pod本身的状态
- 当pod出现问题,replicationController会自动拉起一个新的pod
- 修改replicationController的replicas,可以实现动态扩容缩容
- 修改replicationController的template,可以升级应用(修改之后再删除原有的,因为修改template并不会影响现有的运行中的pod,这是一种停机升级)
1 | apiVersion: v1 |
deployment直接作用的是rs不是pod
replicationSet(rs)就是label选择表达式更加丰富了的rc。
没有deployment的时候,升级的应用的方式有:
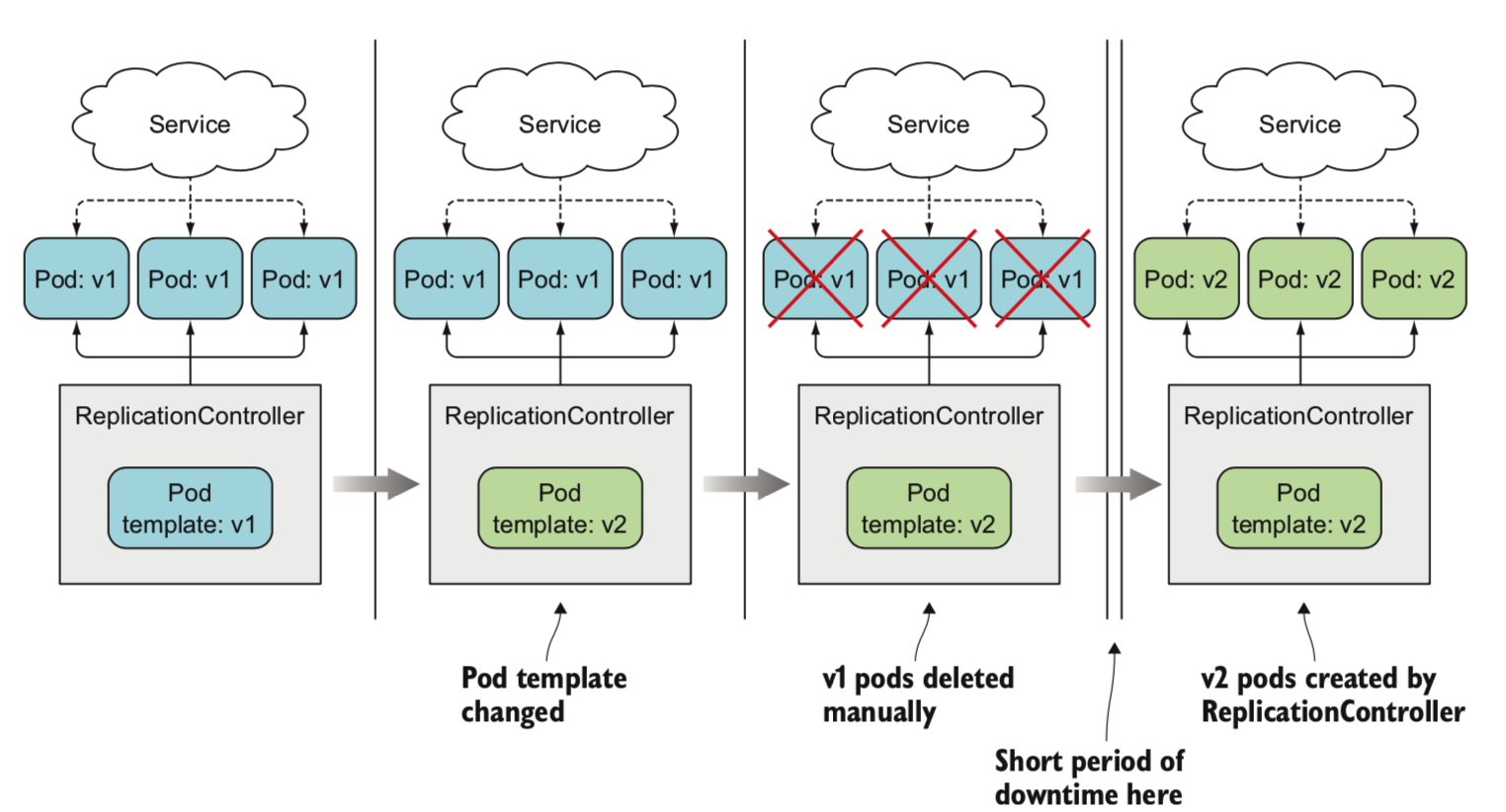
- 使用一个rc,停机升级:先修改template,删除旧pod,然后创建新的pod
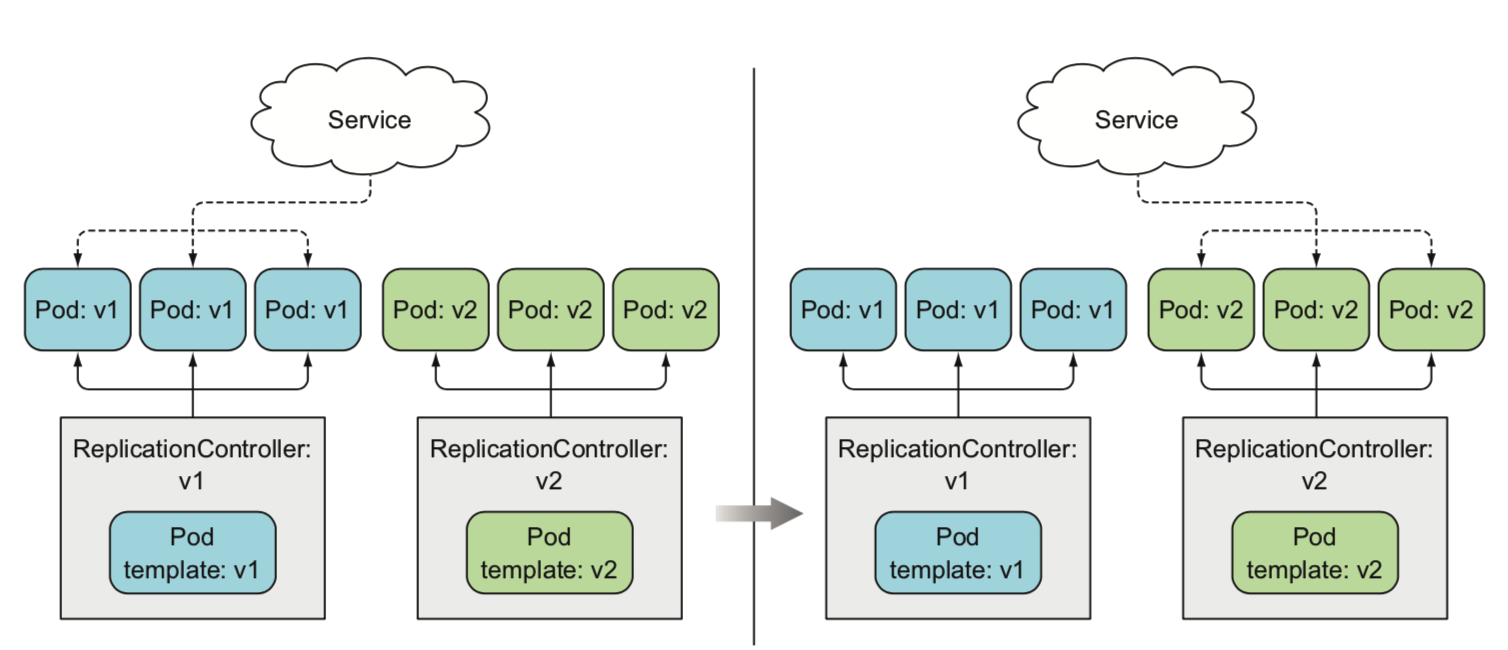
- 使用两个rc,不停机升级:先修改template,删除旧pod,然后创建新的pod
- 手动执行滚动升级
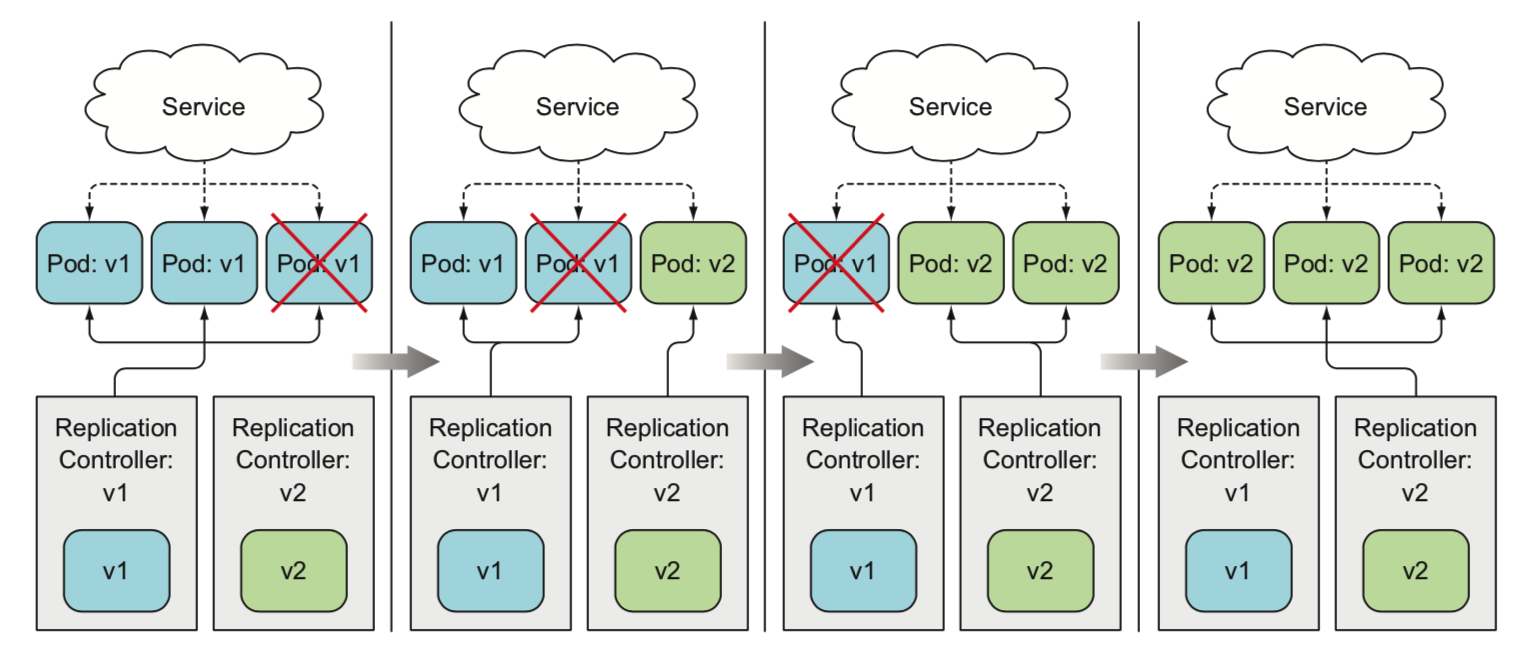
使用了deployment实现自动滚动升级(kubernetes自动控制)
- deployment滚动升级过程也是通过创建新的rs逐步替换旧pod,旧的rs不删除
- 保留旧的rs,方便回滚
- 支持暂停升级(相当于运行了一个金丝雀版本的app)
其他的编排对象
daemon set: 给每个node都创建一个pod
eg:kube-proxy,日志搜集程序,servicemesh网格/sidecar
job:一次性任务/定时任务
stateful set:有状态的pods的编排对象
其他编排方式:蓝绿/金丝雀(灰度)…
https://github.com/ContainerSolutions/k8s-deployment-strategies
3. service - 让客户端发现pod&和pod通信
service主要解决两个问题:
- pod随机调度引起的pod应用定位的问题
- pod的流量的负载均衡
service提供稳定的ip地址来访问pod
service的ip地址是虚拟ip地址(vip),无法ping通
1 | apiVersion: v1 |
服务发现
主要通过环境变量和DNS用于发现服务
环境变量
XXX_SERVICE_HOST
XXX_SERVICE_PORT
(XXX为服务名字)
DNS
{service_name}.{namespace}.{可配置的集群域后缀}
eg:kubia.default.svc.cluster.local
连接外部服务
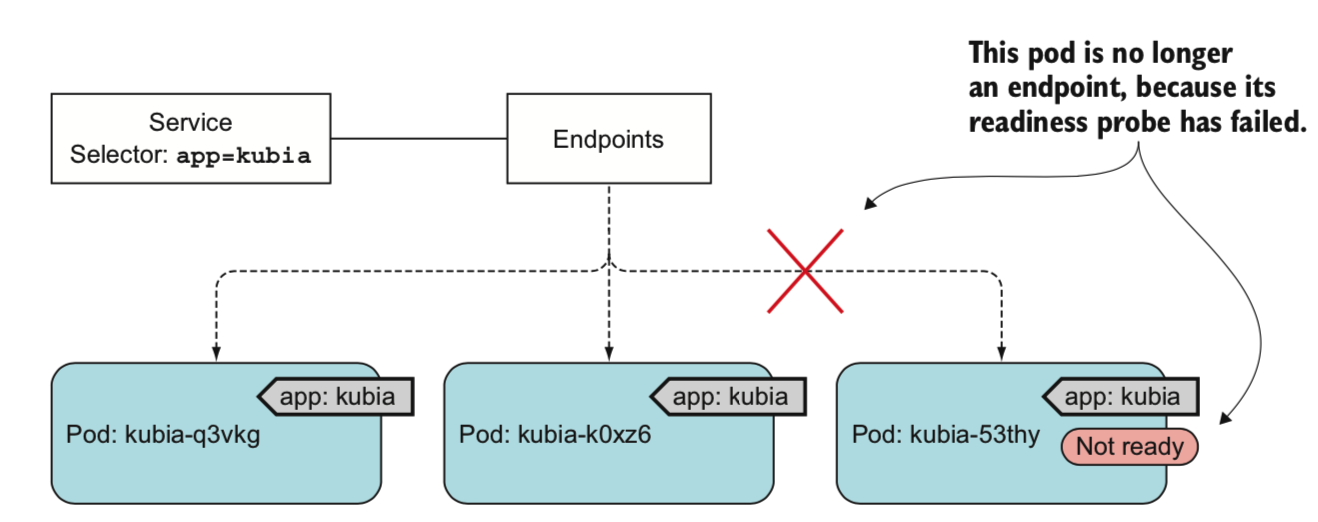
连接service和pod的是一种叫做endpoint的资源,endpoint资源是一组服务的ip地址和端口列表
手动配置endpoint指向外部的ip/域名,可以使得服务得以访问相应的外部服务
对外暴露服务
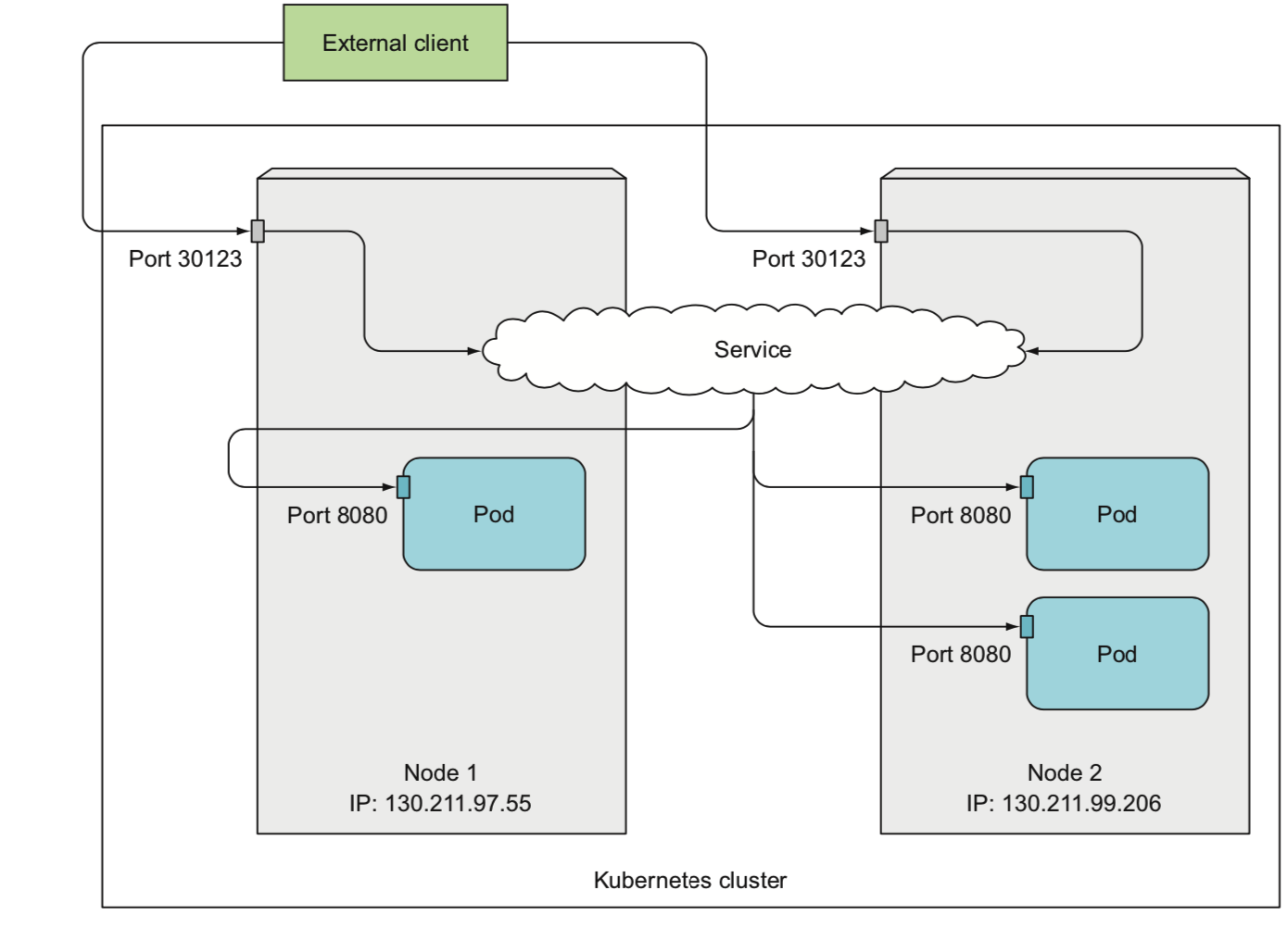
nodeport
把任意集群节点的端口的流量转发到内部的service ip端口
1 | apiVersion: v1 |
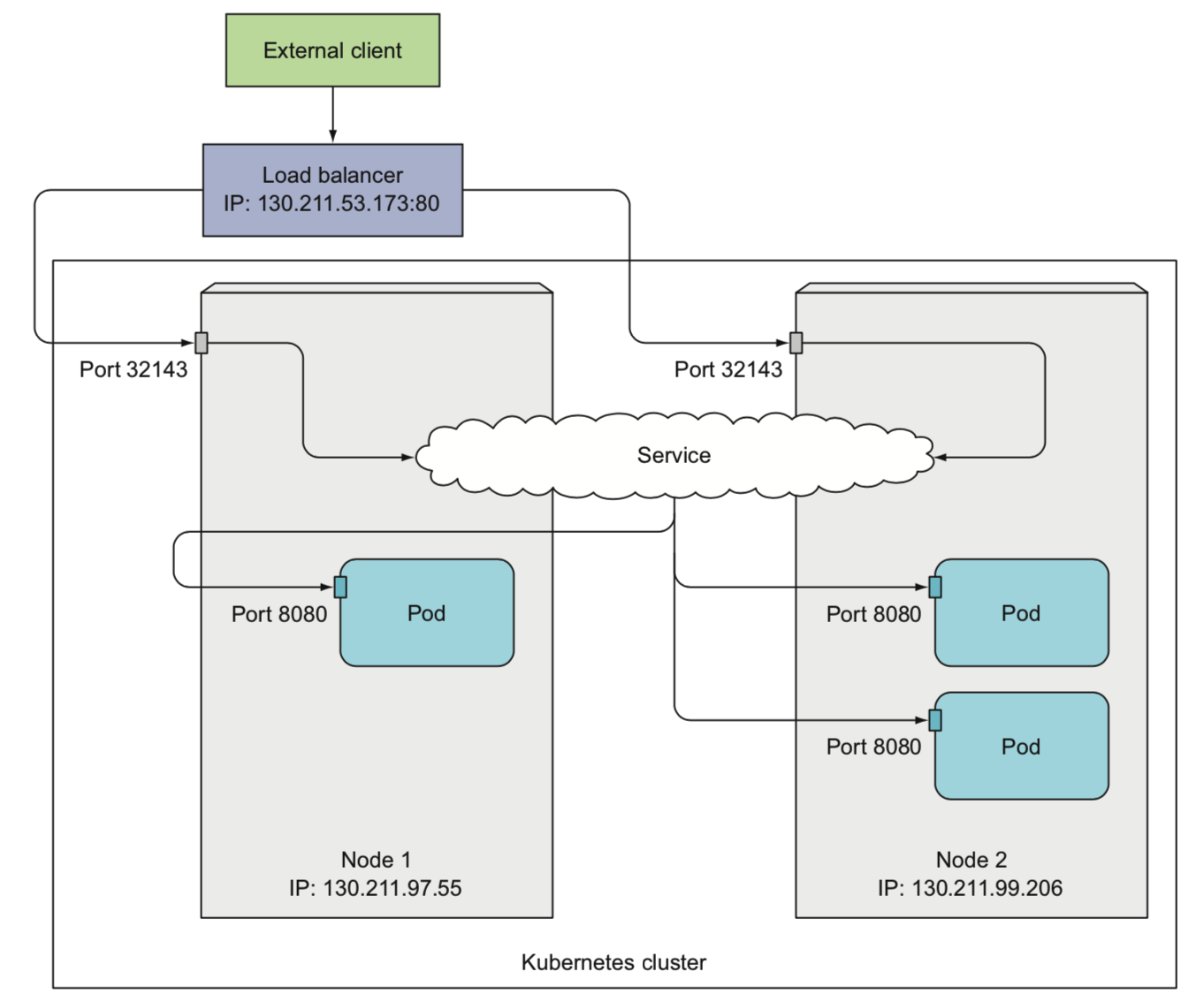
负载均衡器
在nodeport基础上做了一层负载均衡
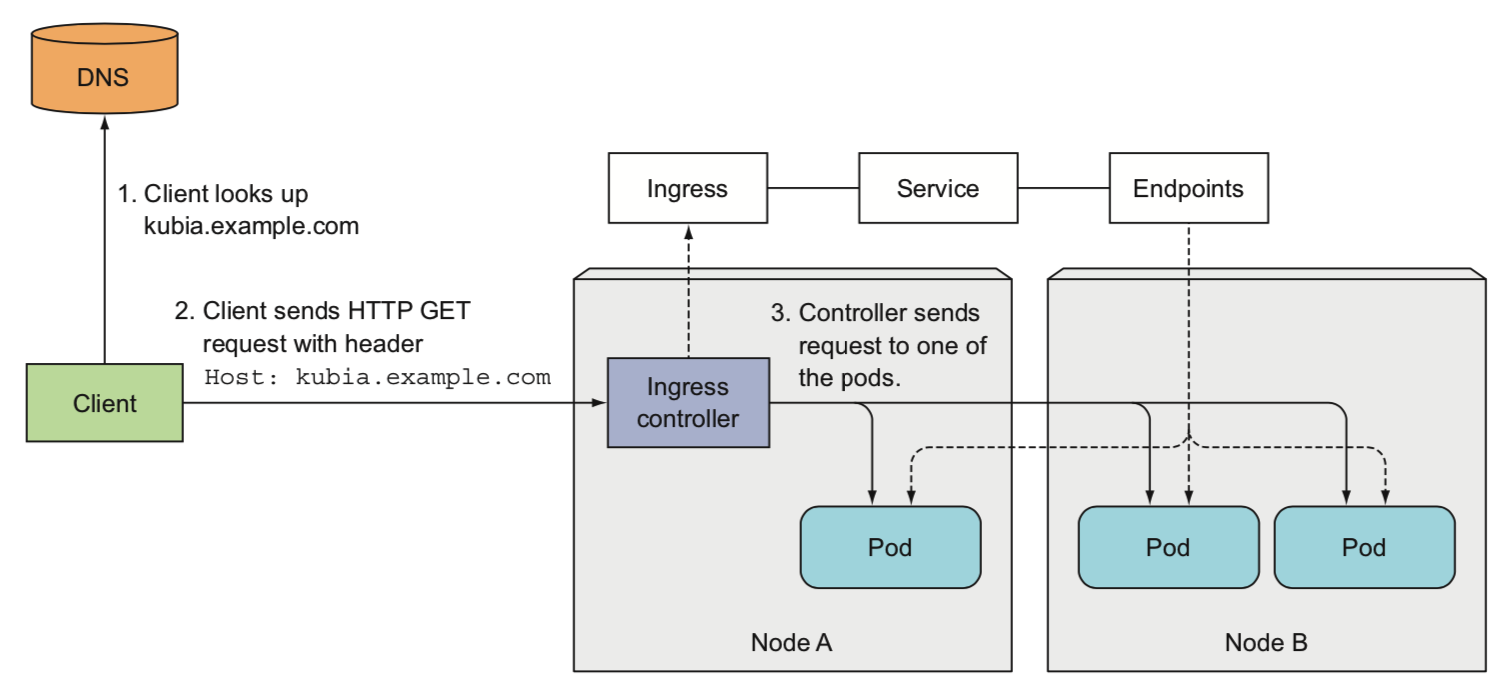
ingress
ingress提供多个服务的负载均衡,本质上是k8s对反向代理的一种抽象(nginx/haproxy…)
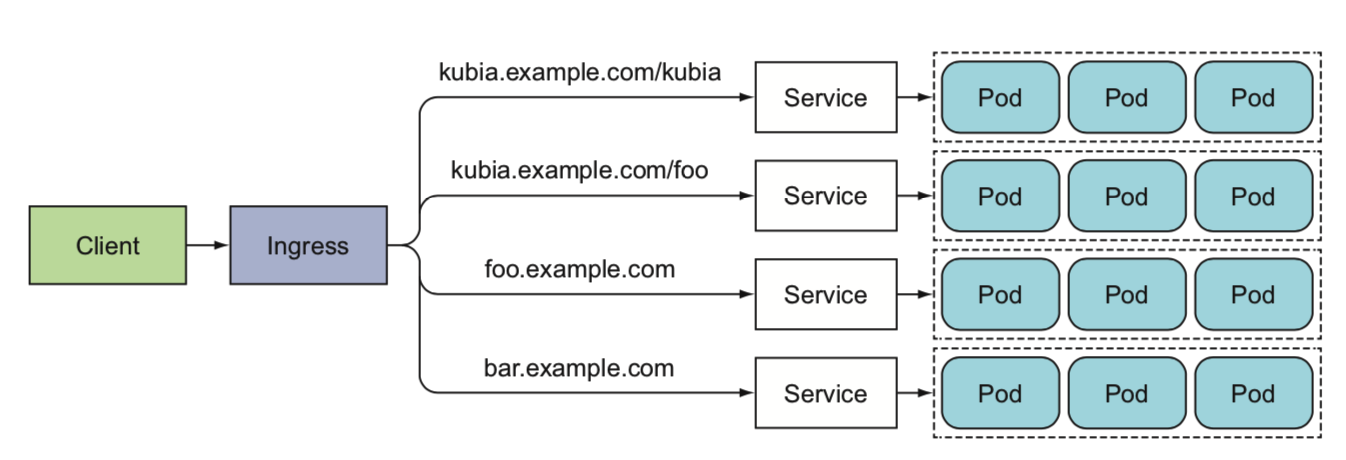
ingress不转发请求给service,而是通过service来选择一个pod
headless服务
通过讲服务的spec配置项clusterIP设置为none,DNS查询不返回service的vip,而是返回多个A记录(每个pod一个)
4. volume - 将磁盘挂在到pod中
docker的文件系统来自于镜像,通过volume实现pod中多个容器的文件共享
常用volume
emptyDir
磁盘临时文件,pod删除,卷内容会被回收
hostPath
挂载工作节点(host机器)上的文件,类似于shopee的日志
gitRepo
git仓库同步的目录(不能一直保持同步)
persistence volume
Pv/pvc/storage class
pvc:持久卷声明,面向用户(开发),类似于接口。是用户需求清单的抽象
pv:持久卷,面向运维,类似实现了pvc的对象,运维可以随意替换存储介质的实现
storage class:实现了pvc的类,可以通过storage class模版化的生成pv
Projected Volume
常用配置应用程序的方式有:命令行参数/配置文件读取/环境变量读取。
projected volume是配置资源的抽象,但是最终让用户/应用进程所感知的方式同样是上面三种
抽象配置资源,可以独立配置声明的yaml文件和部署资源的yaml文件
configmap
存储非敏感的文本配置数据
secret
用于传递证书/私钥之类的敏感数据
downward api
用来和k8s通信/获取pod元数据的
ServiceAccountToken
kubernetes运行原理
组件
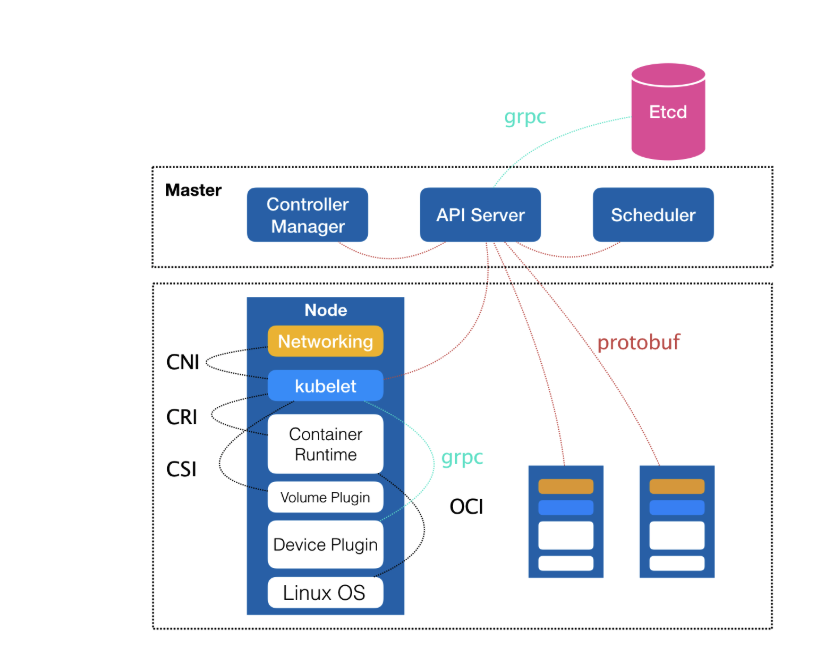
k8s组件主要分为:
- 控制面板
- etcd
- apiserver
- scheduler
- controller manager
- 工作节点
- kubelet
- kube-proxy
- 容器运行时
- 附加组件
- K8s DNS服务器
- dashboard
- ingress控制器
- 集群监控
- CNI(容器网络接口插件)
几个点:
- etcd是唯一的存储组件(raft协议,线性一致性的存储系统)
- apiserver是唯一的和etcd交互的组件(apiserver实现了乐观锁机制,能保证冲突被正常处理)
- apiserver以外的组件之间的通信都是通过apiserver进行
- etcd和apiserver是多实例同时运行,其他组件虽然多实例,但只有一个主节点处于工作状态(利用etcd选举)
- 除了kubelet外,其他组件都可以作为pod来运行
1) etcd - 存储介质
2) apiserver - k8s的api,类似系统调用之于于操作系统
集群资源和状态的crud
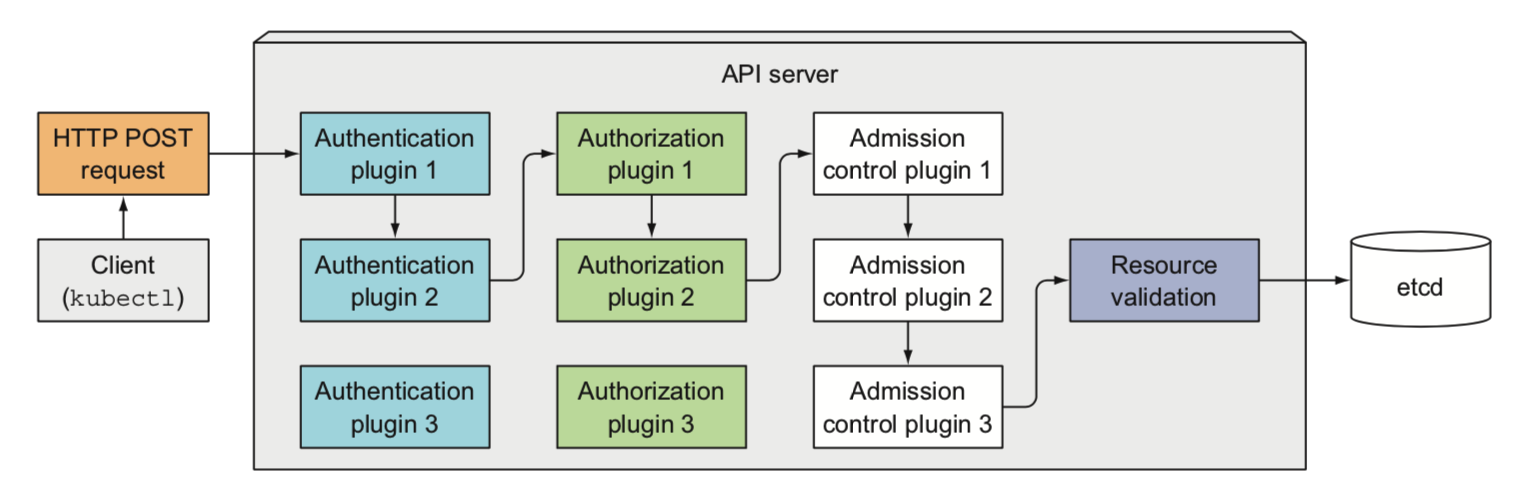
资源变更的通知
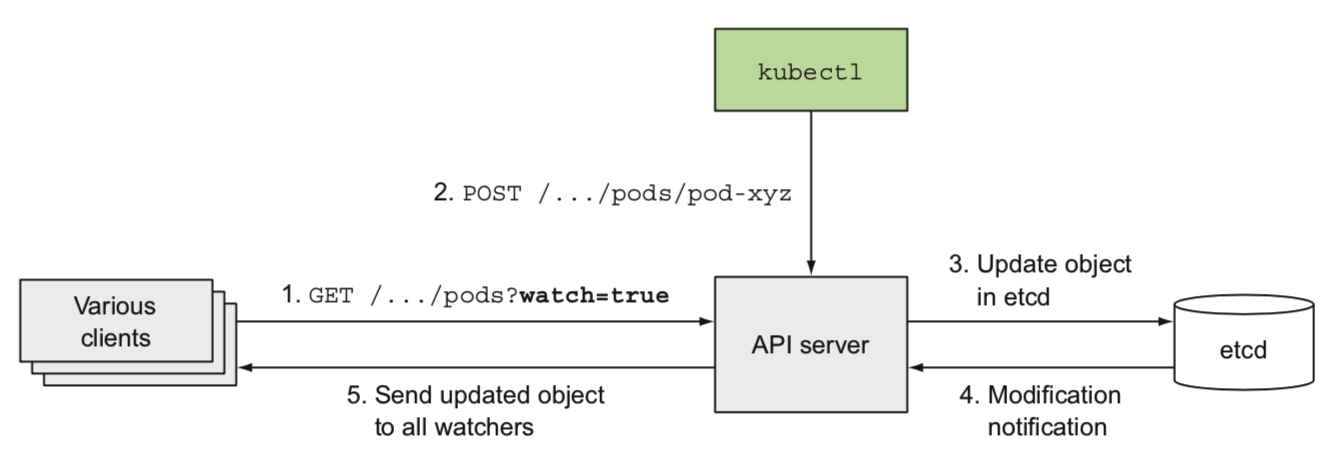
3) 调度器 - 分配节点
调度器调度流程:
- 调度器监听api server中所有更新的pod的定义
- 选择一个合适的节点(涉及到调度策略)
- 更改pod中
nodeName的声明 - apiserver通知对应节点的kubelet
- kubelet部署pod
4) controller manager - 让集群状态向api定义的期望状态收敛
控制器包括
- deployment controller
- node controller
- service controller
- endpoints controller
- namespace controller
- …
有些controller依赖外部组件,比如ingress controller,就是坚挺apiserver里ingress资源的变更,然后更新ingress的基础设施(nginx/haproxy等)的配置,动态修改配置,让集群的状态变成我们期待的状态(资源声明)
5) kubelet
主要工作有:
注册node到apiserver
启动pod容器
持续监控容器,向apiserver报告
6)kube-proxy
Cluster IP与NodePort等概念是kube-proxy服务通过iptables的NAT转换实现的,kube-proxy在运行过程中动态创建与Service相关的iptables规则,这些规则实现了将访问服务(Cluster IP或NodePort)的请求负载分发到后端Pod的功能
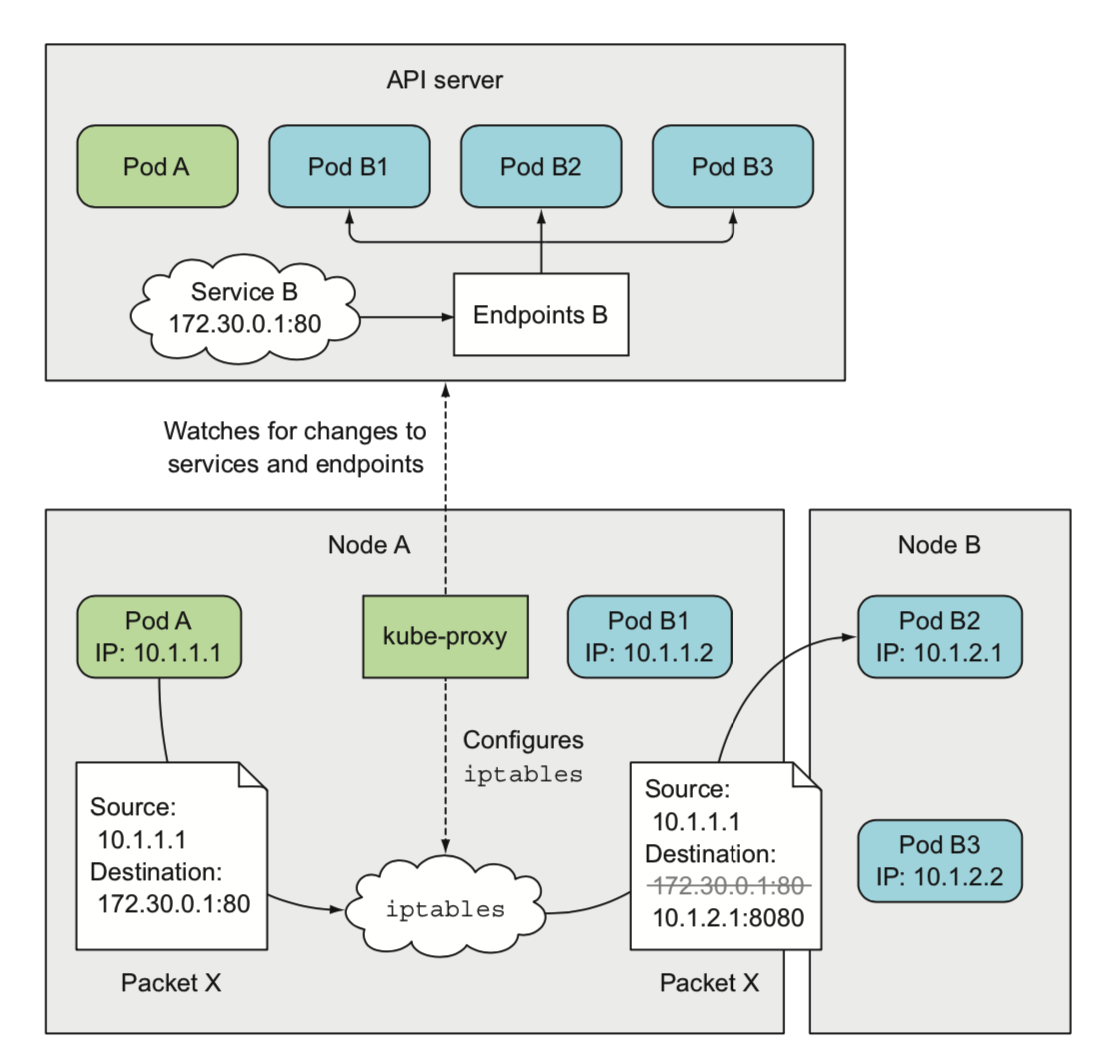
运行模式
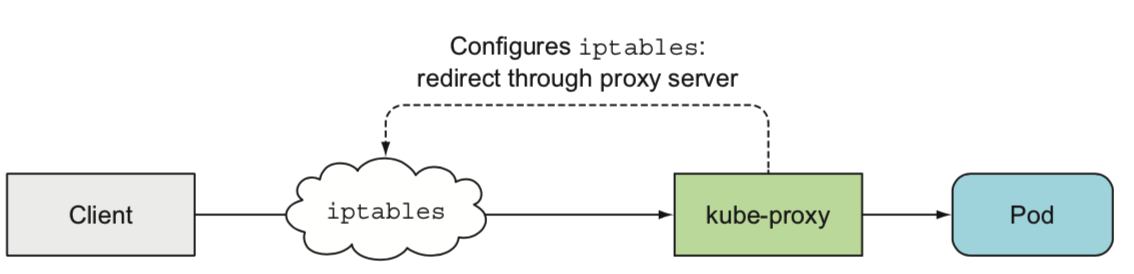
最开始用于修改iptable规则,同时作为proxy组件代理请求进出,所以叫kube-proxy(性能差, 内核和用户态之间传输数据)
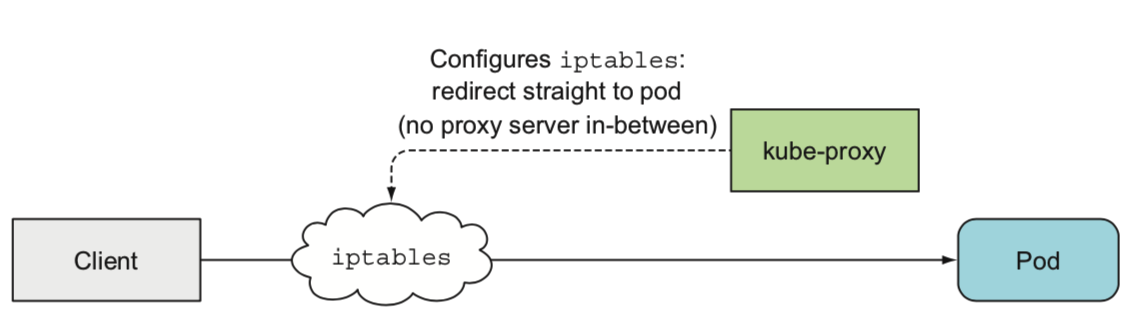
完全iptable模式,性能较高
7) 插件
通过yaml声明,作为daemonset/deployment/replicationController资源部署
控制器工作流
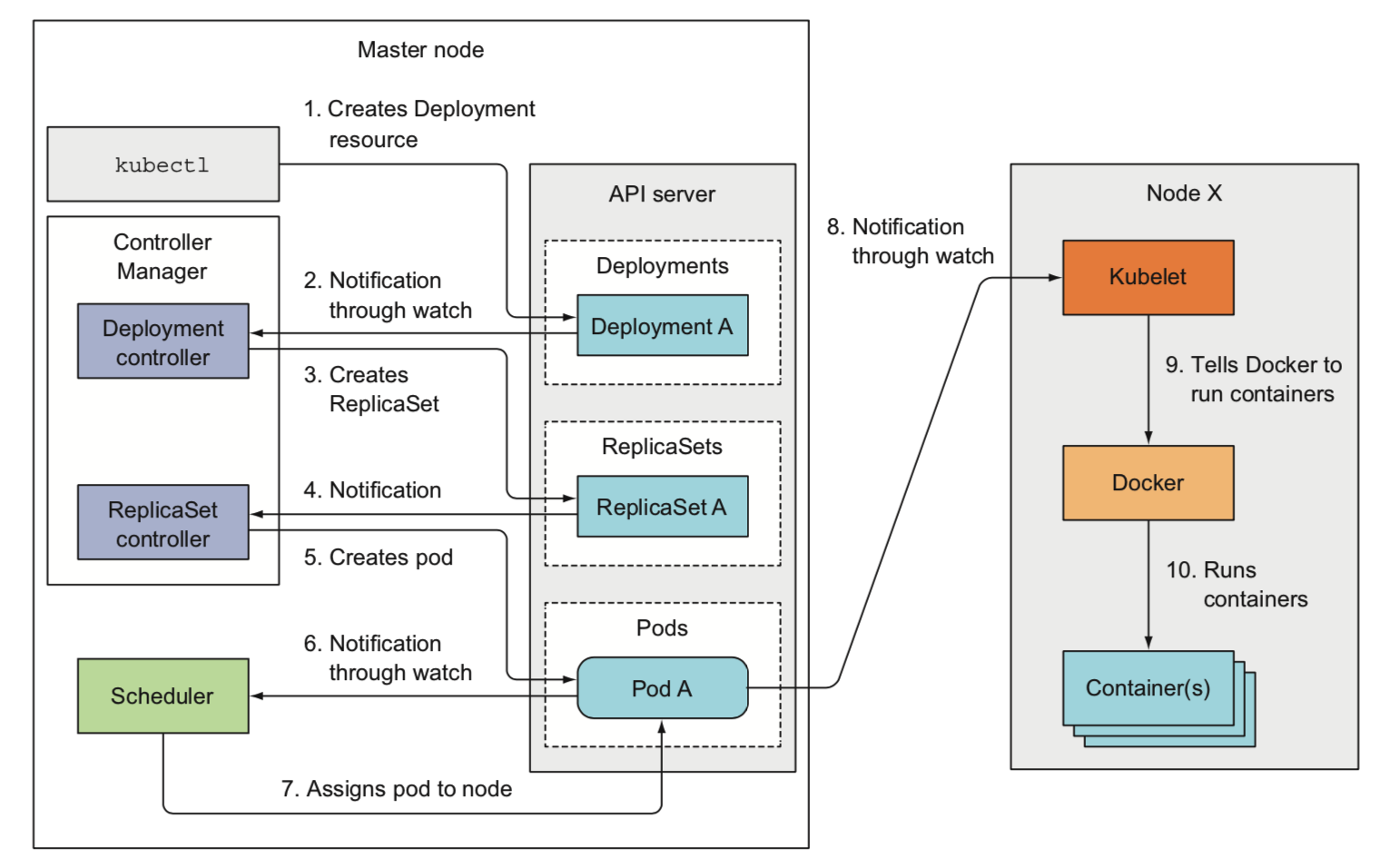
所有组件执行动作的时候都会生成一个事件资源发送给apiserver,可以直接观测到
跨pod网络(service/DNS/服务发现)
k8s的网络的原则:
- 每个pod具有唯一的ip
- pod之间的通信没有NAT
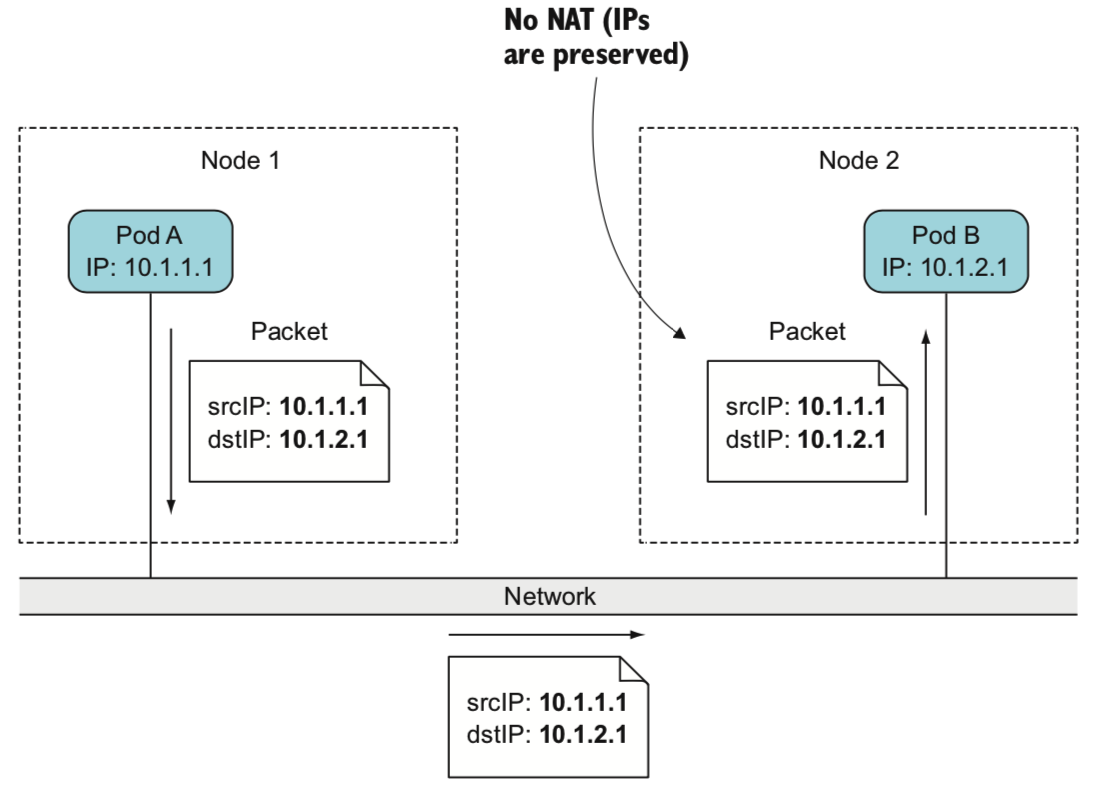
1. 同一个pod内不同的容器通信
同一个pod内的容器共享net namespace,共享协议栈,等同于在相同主机通信
2. 同一节点的通信原理(和docker的CNM一样
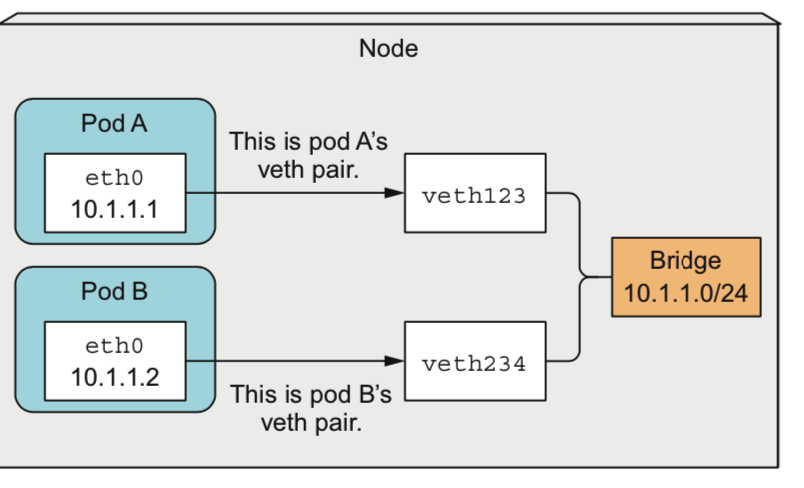
桥接网络模式
Pod a ping pod b:
- ping进程构造ICMP echo请求包,并通过socket发给协议栈,
- 协议栈根据目的IP地址和系统路由表,知道去10.1.1.2的数据包应该要由10.1.1.1口出去
- 由于是第一次访问10.1.1.1,且目的IP和本地IP在同一个网段,所以协议栈会先发送ARP出去,询问10.1.1.1的mac地址
- 协议栈将ARP包交给eth0,让它发出去
- 由于eth0的另一端连的是veth123,所以ARP请求包就转发给了veth123
- 由于veth123的另一端连的是bridge,所以ARP请求包就转发给了bridge
- arp包继续到达beth234和podb的eth0
- eth0把arp包往上抛给协议栈,协议栈发现自己的设备有这个ip,返回arp应答(没有就抛弃
ps:公司使用的是host网络(容器和宿主机具有相同的ip地址
3. 跨节点的通信原理
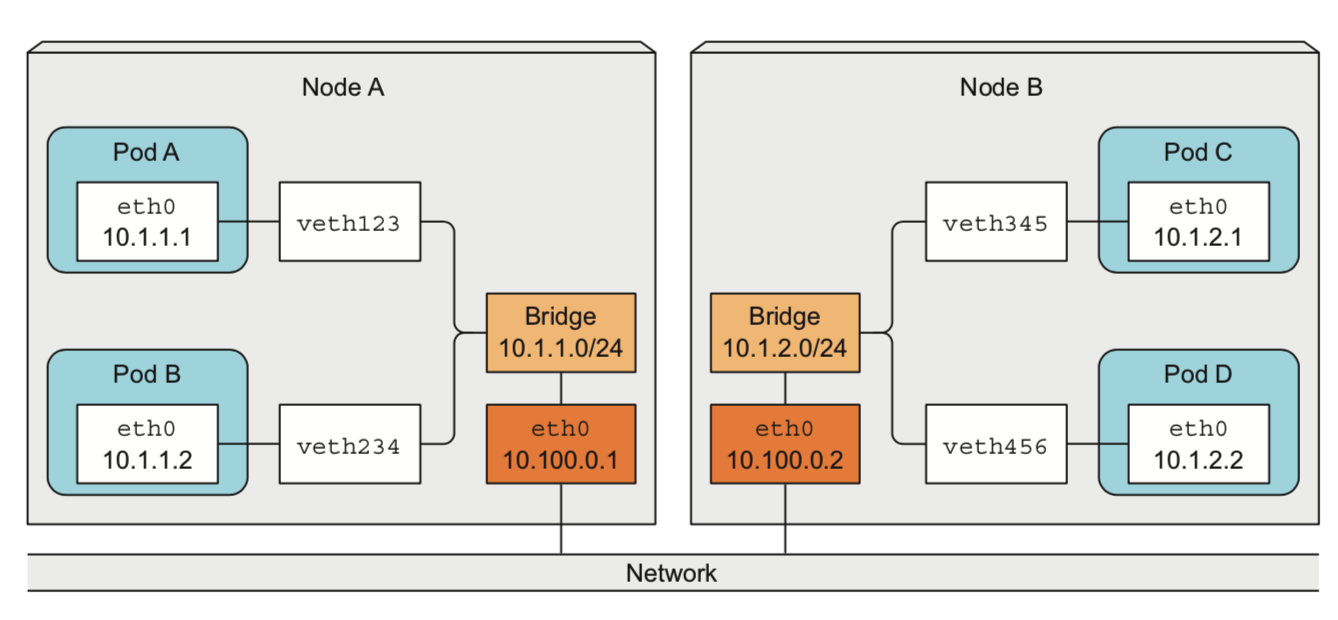
不同节点之间的网桥以某种形式连接
三层网络
二层网络
具体由CNI插件来实现
- calico
- flannel
- udp
- vxlan
- Host-gw
UDP
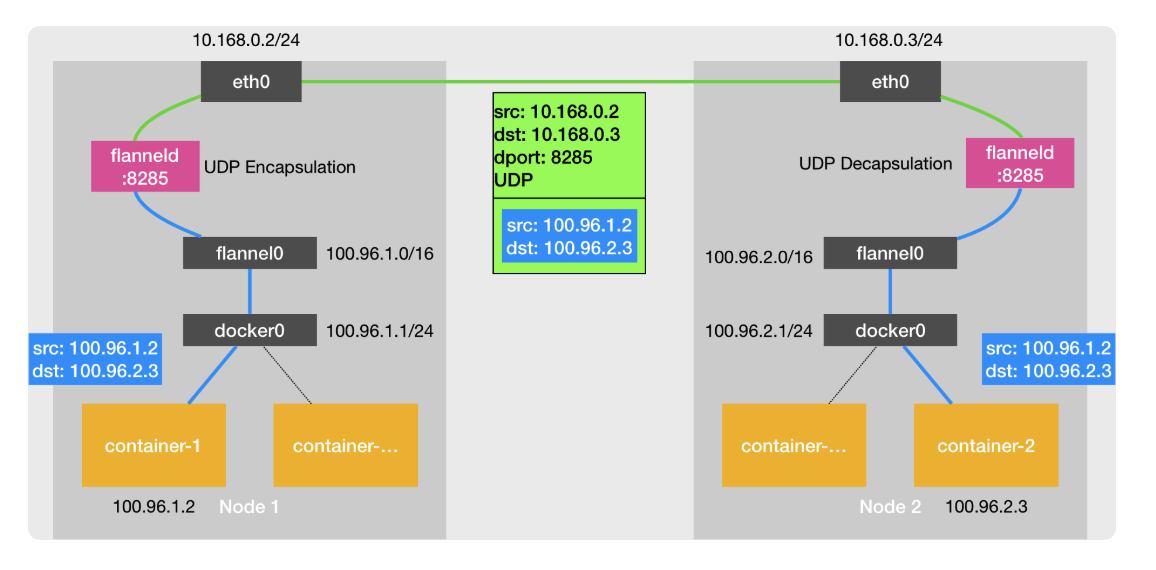
- Docker0(br)通过host机器上的路由表,转发请求到flannel0
- flannel0是一个tun设备,把请求转发到用户空间的flanneld程序
- flanneld查找etcd,找到目的容器ip对应的节点ip
- 套娃一层ip包
- 通过宿主机etho0转发udp包到公网
- …
vxlan
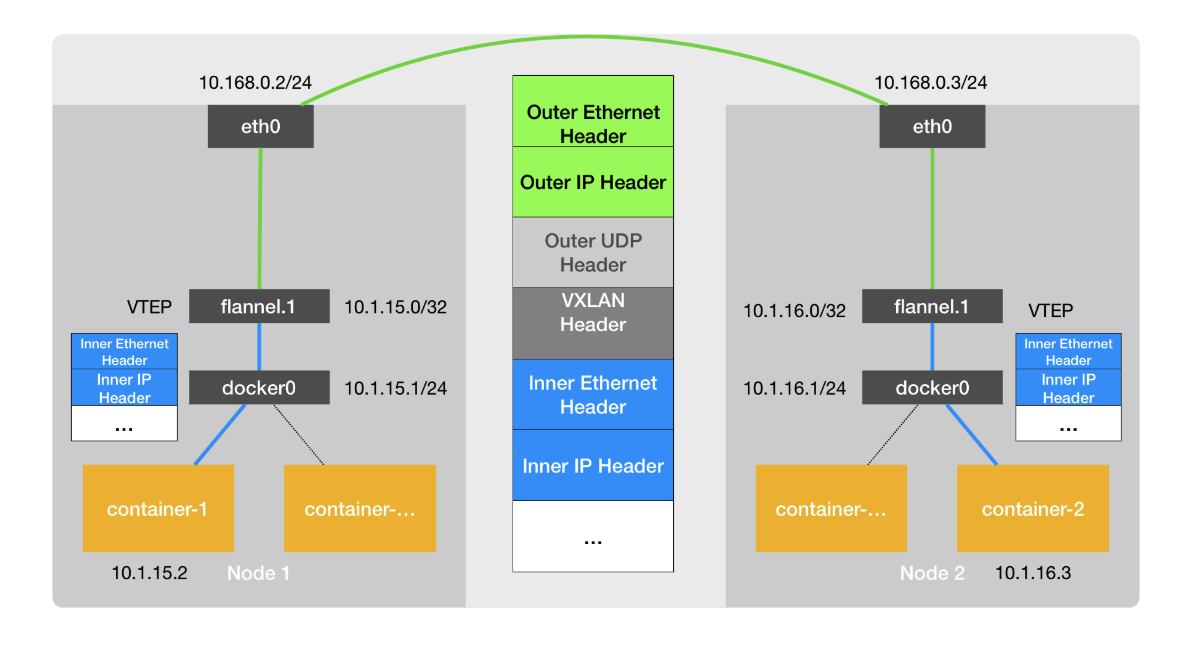
在现有的三层网络之上,“覆盖”一层虚拟的、由内核 VXLAN 模块负责维护的二层网络,使得连接在这个 VXLAN 二层网络上的“主机”(虚拟机或者容器都可以)之间,可以像在同一个局域网(LAN)里那样自由通信
目的 VTEP 设备的arp表在节点创建的时候生成
host-gw
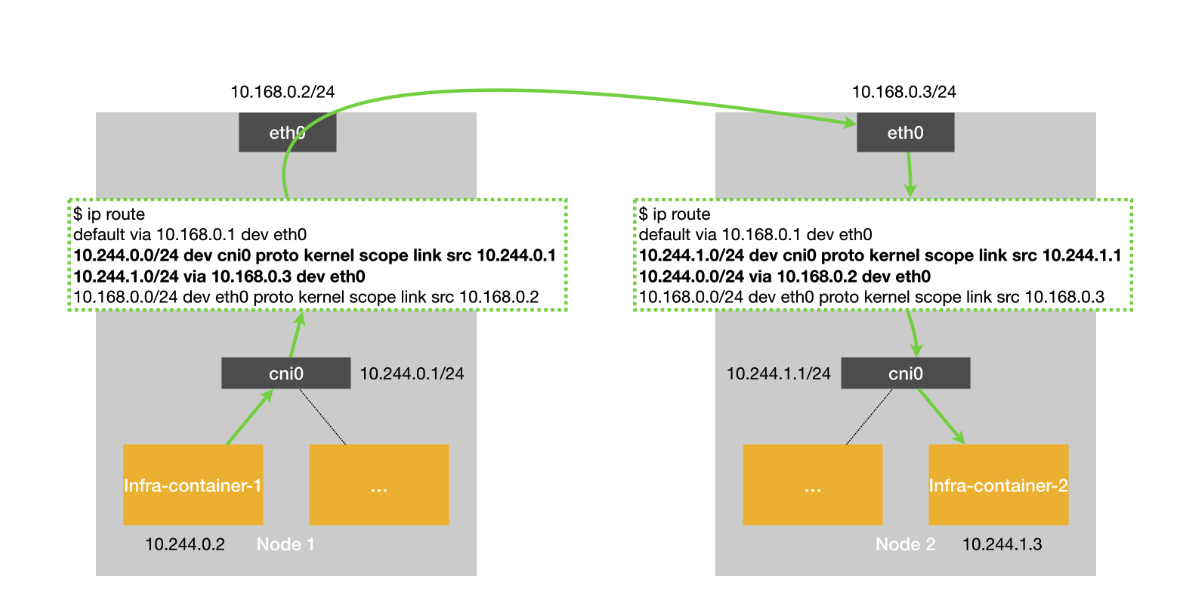
- 路径更短,性能更高
- 但是节点之间必须是二层联通的(通过路由表吓一跳mac地址设置目的地址,通过二层网络传输
常用kubectl的命令(持续更新
资源信息
- kubectl explain po/ns …
pod
pod
创建pod - 通过yaml文件
kubectl create -f xxx.yaml
查看运行时pod的完整定义
kubectl get po poname -o yaml(-o 表示格式yaml/json)
查看pod日志
kubectl logs podname (只有一个容器时候)
kubectl logs podname -c containername (不只有一个容器时候)
本地ssh端口转发
kubectl port-forward podname localPort:podPort
删除pod
kubectl delete po podname
kubectl delete po -l labelKey=labelValue
kubectl delete ns nsName
kubectl delete po –all
kubectl delete all –all
label
- 创建标签
- 通过命令
- 通过yaml文件
1 | xxx |
查看标签
- 列表带标签
kubectl get po –show-labels
Kubectl get po -L labelkey1,labelkey2
- 通过标签过滤
Kubectl get po -l labelkey
Kubectl get po -l labelkey=labelval
Kubectl get po -l labelkey=’!labelval’
修改标签
Kubectl label po podname labelkey=labbelval
Kubectl label po podname labelkey=labbelval –overwrite(修改已存在的)
使用标签分类工作节点
Kubectl label node codename labelkey=labelval
查看pod详细信息
Kubectl describe po podname
添加注解
Kubectl annotate pod podname key=value
namespace
创建命名空间
- yaml
1
2
3
4apiVersion: v1
kind: Namespace
metadata:
name: custom-nskubectl 方式:
kubectl create namespace custom-ns
查看namespace
kubectl get ns
查看namespace中的所有pods
kubectl get po -n namespaceName