分布式基础
本文主要是《Distributed systems for fun and profit》的笔记
一.基础
计算机主要做两个事情:
- 计算
- 存储
1. 为什么要用分布式系统
当单台机器的硬件升级也没法解决问题的时候,就需要分布式系统。理论上来说,添加一个服务节点可以线性提升性能,但是现实中,多台机器还涉及到数据拷贝,任务合作等问题。
1.1 目标
分布式系统,我们想要:可扩展性——数据或者问题规模变大,可以单纯的通过增加节点解决。
扩展性,就要求规模,节点规模从小到大,就会遇到以下问题:
性能
- 低时延
- 高吞吐
- 资源消耗低
可用
- 容错性:允许某些节点失败
- 延时不能过高
Availability = uptime / (uptime + downtime)
| Availability % | How much downtime is allowed per year? |
| ———————- | ————————————– |
| 90% (“one nine”) | More than a month |
| 99% (“two nines”) | Less than 4 days |
| 99.9% (“three nines”) | Less than 9 hours |
| 99.99% (“four nines”) | Less than an hour |
| 99.999% (“five nines”) | ~ 5 minutes |
| 99.9999% (“six nines”) | ~ 31 seconds |
1.2 阻碍
- 节点数量
- 节点的距离
光速传播速度和cpu频率决定了最低时延
2. 如何研究分布式系统
2.1 抽象和模型
抽象可以从现实世界的复杂中得到本质的东西,这种本质就是模型
分布式系统的本质可以归纳为三个模型:
- 系统模型(同步/异步)
- 容错模型(crash-fail/partition/拜占庭问题)
- 一致性模型(强一致/弱一致)
抽象的目的就是为了让这个系统对外看起来像是一个节点。这里有一个矛盾,过分强调一致,会使得使用者容易理解,但是会导致性能不好,可用性降低,适当暴露一些细节会提高性能,但是增加了系统的理解成本。
3 分布式实现
本质上只有两种手段:
- 数据分区(partition)
- 数据复制(replication)
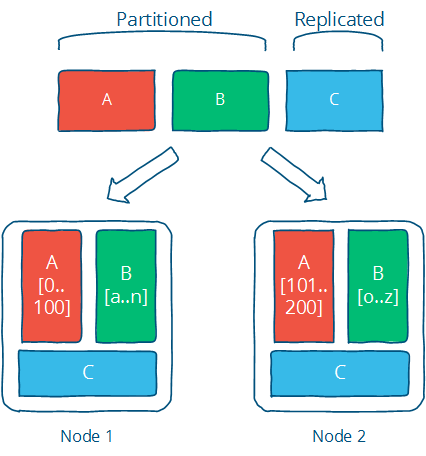
partition可以把数据分成几块,解决了单一节点的存储限制
replication允许我们实现可扩展,容错,但是涉及到数据的同步,是很多问题的源泉,一致性模型就是为了描述这个问题而存在的
二.理论
抽象可以提取实物的本质,再通过这个本质可以推导出某种公理性的东西
系统模型就是分布式系统的抽象
1. 系统模型
分布式系统模型的抽象取决于假设的多少,一般来说,假设越少越好,系统模型有三个基本的假设
- 节点独立运行
- 节点通过网络连接
- 节点之间的内存和时钟不共享
假设越少,推演出来的理论和算法的适用范围越广,如增加假设:节点从来不会失灵,则推演出来的算法会忽略掉节点失灵的错误处理,系统就会变得不健壮。
关于节点——节点提供了:
- 可执行程序
- 数据存储到内存和磁盘
- 本地时钟
节点的状态:
- 失灵(fail)
- crash
- 拜占庭将军问题:(叛徒)
节点通信的两种异常:左边是节点失灵,右边是网络

2. 公理
有了系统模型,我们推演出了一些公理
2.1 FLP理论
假设:
- 节点 Fail by crash (不会出现拜占庭将军问题)
- 网络可靠
- 异步系统模型 消息可能无限delay
结论
在异步通信场景,即使只有一个进程失败,也没有任何算法能保证非失败进程达到一致性
证明见参考
2.2 CAP理论
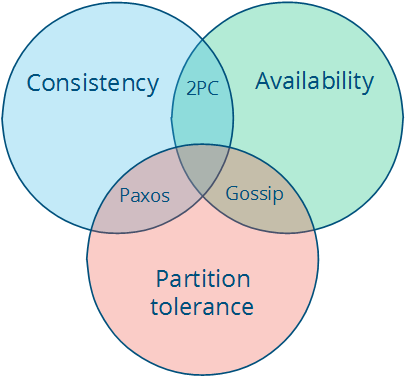
- consistency: 所有节点在同一时刻看到同样的值
- availability:某些节点失效并不影响剩余节点运行
- Partition tolerance:即使因为网络分割或者节点失效造成的消息丢失,系统正常运行
同时满足三个性质的系统是不存在的。
比如你要强一致,并且保证高可用性,任何节点失效系统都不失效,那么对网络分割就没办法容忍了,每条消息都不能丢失。
- CA(Consistency + Availability)如two-phase commit
- CP(Consistency + Partition tolerance)如Paxos,raft
- AP (Availibity + Partition tolerance) 弱一致系统,如gossip
通常,分布式系统我们需要保证P,所以要在CA作取舍
实践中我们大多已经采取了弱一致性的异步延时同步方案,以提高可用性
2.2.1 一致性的扩展
这里,CAP的C理解为多个数据副本的读写一致性问题,其实C可以在很多场景拓展
- 多个数据副本的读写
- 事务
- 关联
关系数据库关于事务操作,必须遵循ACID原则:原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)和持久性(Durability)
这里的C表示一个事务中多个操作成功失败是一致的。
众所周知,分布式事务一般采用两阶段提交策略来实现,这是一个非常耗时的复杂过程,会严重影响系统效率,在实践中我们尽量避免使用它。在实践过程中,如果我们为了扩展数据容量将数据分布式存储,而事务的要求又完全不能降低。那么,系统的可用性一定会大大降低,在现实中我们一般都采用对这些数据不分散存储的策略。
nosql数据库为了实现P,牺牲了C,也即牺牲了事务,事务遵循BASE而不是ACID
三.时间和顺序
3.1 全序和偏序
全序就是在集合里任何两个元素都可以比较,分出大小。偏序中,某些元素是没办法比较大小的。
在分布式的系统里,每个节点的指令运行顺序都取决于本地节点的时钟,所以分布式系统是偏序。
3.2 时间匀速流逝
时间是顺序的来源,分布式系统中每个节点都有独立的本地时间和时间戳,于是事件的发生有本地的顺序,但是该顺序和其他节点完全独立,很难做到全部节点有序。当然也不是做不到全序,维持一个全局时钟就是一种方法,只是这种方法的代价太大。
- 全局时钟(Global Clock)
- 本地时钟(Local Clock)
- 没有时钟存在(No Clock)
3.2.1 全局时钟
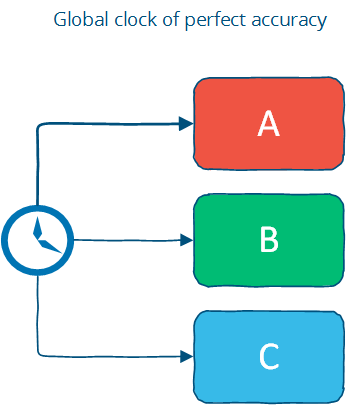
完美的时钟,走时同步,存在于所有节点。这是分布式系统的理想假设。实际上,时钟同步只能保证有限的精度。用户可能随机地改变本机时间,新节点加入,都有可能破坏全局时钟的假设。
现实系统也有做出这个假设的。FB的Cassandra,就是使用时间戳来解决write的冲突的
3.2.2 本地时钟
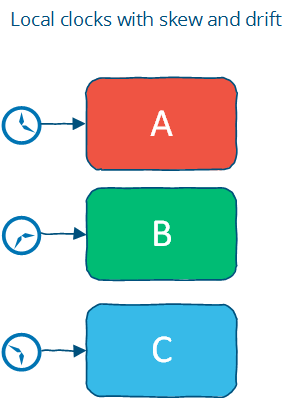
本地时钟无法保证全局有序
3.2.3 没有时钟
完全不使用”时钟”这个概念,取而代之,“逻辑时间”。因为时间戳么,只不过是当前世界状态的一个快照,那我们用一个计数器(Counter),并和节点之间交流就可以做到了。
这样,我们可以在不同的节点之间决定事件顺序。不过有个坏处,因为缺乏时钟,没办法决定timeout。
“没有时钟”的假设的实现有:
Lamport时钟
Vector clocks
Cassandra的cousin Riak 和 Vodemort(LinkedIn)是它的应用。这些系统避免了全局or本地时钟漂移带来的不确定性。
3.2.4 逻辑时钟
Lamport时钟和向量时钟通过计数器和通信来决定分布式系统中事件发生顺序的。计数器可以在不同节点之前进行比较。
3.2.4.1 Lamport时钟
每个进程都维护一个计时器。
- 当进程做了任意一件事,增加计时器计数。
- 进程发送的消息中包含计时器计数。
- 当收到消息以后,计数器设置如下:max(local_counter, received_counter) + 1
Lamport时钟定义了一个偏序,如果 timestamp(a) < timestamp(b):
- a 可能发生在b之前
- a和b压根没法比较
第二种情况发生在a和b所在的Partition没有发送通信。
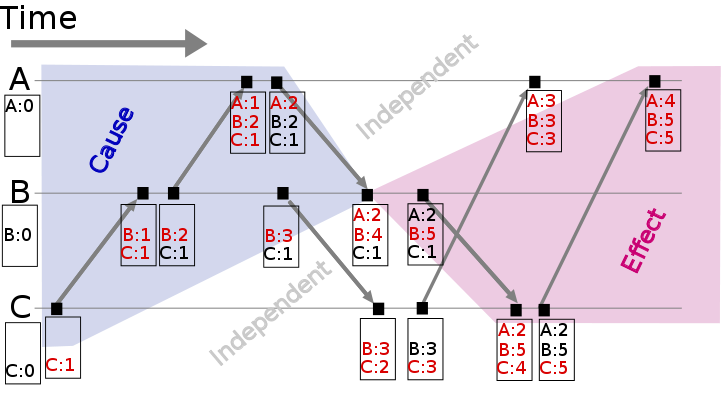
3.2.4.2 Vector clocks
向量时钟是Lamport时钟的一种扩展。它维护大小为N的数列[t1, t2, ….],N为节点数。每个节点都更新自己的时钟。
- 每当进程做了事情,更新该node的时钟。
- 进程发送的消息,包含上面提到的数组。
- 当收到消息以后,更新本地的数组里面的每个元素max(local, received);为当前节点的counter加1
如图:
3.3 失灵检测
对于一个节点上的程序,它怎么知道远程某个节点失效了呢?在缺乏有效准确的全局信息下,我们可以通过一个合理的timeout值来确定。但是合理的timeout值该怎么确定呢?
失灵检测器可以通过使用心跳消息来实现timeout。节点之间交换心跳消息。如果消息在timeout之前没有收到响应,就可以认为出现失效。这种检测要么太冲动(把正常的节点算成失效),要么太保守,很长时间才能检测出错误。
论文 讨论了失灵检测在解决一致性问题中的两大属性:完整性和精准性
3.4 总结
在分布式系统中应假设偏序而不是全序。而要承诺全序也是可能的,但是代价非常大。
时间,顺序和同步真的必要么?看情况。有时候可能你只不过需要最后的结果而不关系中间事件发生的顺序。
四.replication
拷贝其实是一组通信问题,为一些子问题,例如选举,失灵检测,一致性和原子广播提供了上下文
拷贝本质就只有两种:
- 同步拷贝
- 异步拷贝
4.1 拷贝范式
4.1.1 同步拷贝

首先client发送请求。然后同步拷贝,同步意味着这时候client还在等待着请求返回。最后,服务器返回。
这就是N-of-N write,只有等所有N个节点成功写,才返回写成功给client。系统不容忍任何服务器下线。从性能上说,最慢的服务器决定了写的速度
4.1.2 异步拷贝
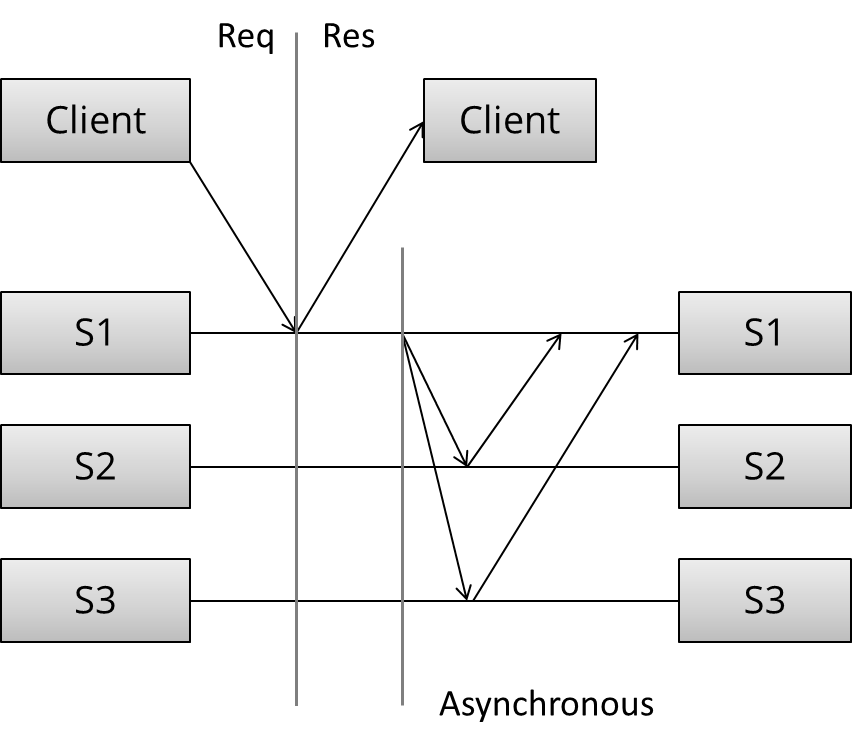
master节点立即返回。该节点可能在本地做了复制,但是不会向其他服务器发送拷贝。只有在返回以后,异步的任务在开始执行。
相对地,这是1-of-N write。性能上说,快。但是不能提供强一致性保证。
4.2 拷贝算法
4.2.1 overview
一致性的强弱可以用来区分拷贝算法
一致性就是所有的节点都同意某一个值,具体的说,一致性包括:
协议:每个正确的流程必须就相同的价值达成一致。
完整性:每个正确的过程最多决定一个值,如果它决定某个值,那么它必须由某个过程提出。
终止:所有流程最终都会做出决定。
有效性:如果所有正确的过程提出相同的值V,那么所有正确的过程决定V
互斥,leader选举,多播和原子广播都是更普遍的一致性问题
单拷贝系统按照一次执行中传递的消息数目,可以做一下分类:
- 1n messages(异步 主从备份)
- 2n messages(同步 主从备份)
- 4n messages(2-phase commit,Multi-Paxos)
- 6n messages (3-phase commit,Paxos with repeated leader election)
![]()
上图列出的复制算法不难发现,一致性强的算法,相应的延时高,性能低,这是一种取舍,得此失彼。
4.2.2 主从备份拷贝
最常见最基本的拷贝方式。所有的update发生在primary,并且以log的形式拷贝到backup 服务器。主从备份也分同步和异步两种。
MySQL和MongoDB都使用异步主从备份。同步主从备份保证在返回给client之前,backup节点成功存储了拷贝(Replica)。不过即使这样,同步方式也仅能保证较弱的承诺。考虑下面的场景:
- 主服务器收到write,发送到backup
- backup 写成功。返回ACK
- 主服务器fail,client超时,认为写失败。
client现在认为写失败,但是backup其实成功。如果backup promote成为primary,那么就不对了
4.2.3 两阶段提交(2PC)
2PC在很多经典的关系型数据库中都使用到了。例如MySQL 集群使用2PC提供同步拷贝。下面是2PC的基本流程
1 | [ Coordinator ] -> OK to commit? [ Peers ] |
在第一阶段,投票,协调者(Coordinator)给所有参与者发送update。每个参与者投票决定是否commit。如果选择commit,结果首先存放在临时区域(the write-ahead log)。除非第二阶段完成,这部分都只算“临时”的update。
在第二阶段,决策,协调者决定结果,并通知参与者。如果所有参与者都选择commit,那结果从临时区域移除,而成为最终结果。
2PC在最后commit之前,有一个临时区域,就能够在节点失效的时候,从而允许回滚。
之前讨论过,2PC属于CA,所以它没有考虑网络分割,对网络分割并没有容错。同时由于是N-of-N write,所以性能上会有一些折扣
4.2.4 对网络分割容错的一致性算法:gossip/raft和ZAB
对网络分割容错的一致性算法其实就是实现了CAP的CP,同时保重了一定的A。
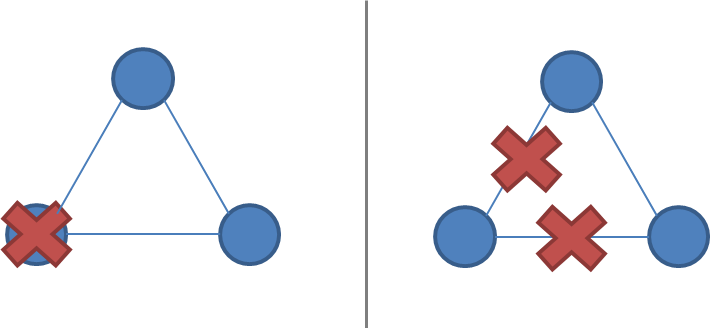
什么是网络分割(Network Partition)
节点本身正常运行,但是网络链路发生问题。不同的Partition甚至还能接收client的请求。
2节点,节点失效 vs 网络分割
3节点,节点失效 vs网络分割
对这类算法会在学习MIT6.824公开课深入学习,to be continues…
4.3 总结
总结下各类算法的一些关键特征。
主从备份
- 单独的,静态的master节点
- 复制日志,slaves节点并不参与执行具体操作
- 拷贝操作的延时没有上限
- 无法容错网络分割
- 在不一致和错误发生情况下,需要手工干涉
2PC
- 统一投票:提交或者放弃
- 静态的master节点
- 协调者和普通节点同时挂掉情况下无法保证一致性
- 无法容错网络分割
Paxos like
多数投票
动态master节点
允许n/2-1节点挂
对延时并不太敏感
遗留的问题
- 拜占庭将军问题
- 2PC
- flp实现